PyGAS: Auto-Scaling GNNs in PyG
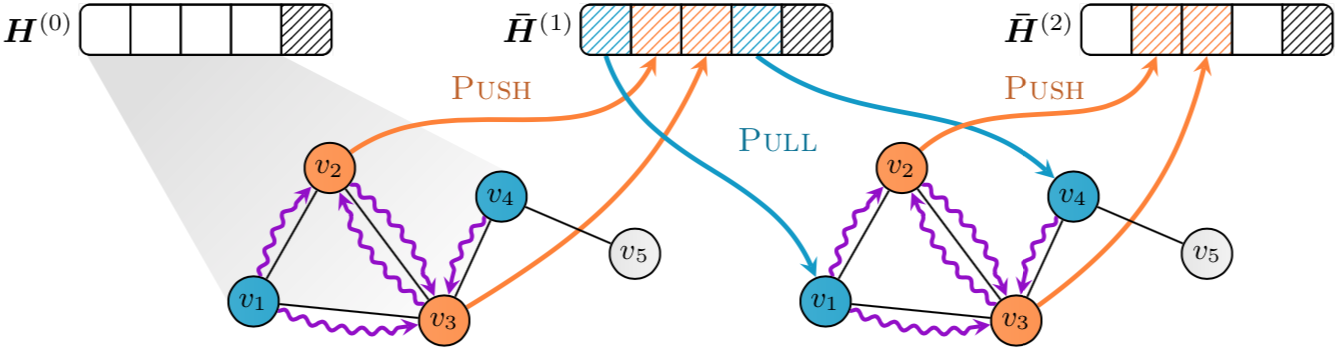
PyGAS is the practical realization of our GNNAutoScale (GAS) framework, which scales arbitrary message-passing GNNs to large graphs, as described in our paper:
Matthias Fey, Jan E. Lenssen, Frank Weichert, Jure Leskovec: GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings (ICML 2021)
GAS prunes entire sub-trees of the computation graph by utilizing historical embeddings from prior training iterations, leading to constant GPU memory consumption in respect to input mini-batch size, and maximally expressivity.
PyGAS is implemented in PyTorch and utilizes the PyTorch Geometric (PyG) library. It provides an easy-to-use interface to convert a common or custom GNN from PyG into its scalable variant:
from torch_geometric.nn import SAGEConv
from torch_geometric_autoscale import ScalableGNN
from torch_geometric_autoscale import metis, permute, SubgraphLoader
class GNN(ScalableGNN):
def __init__(self, num_nodes, in_channels, hidden_channels,
out_channels, num_layers):
# * pool_size determines the number of pinned CPU buffers
# * buffer_size determines the size of pinned CPU buffers,
# i.e. the maximum number of out-of-mini-batch nodes
super().__init__(num_nodes, hidden_channels, num_layers,
pool_size=2, buffer_size=5000)
self.convs = ModuleList()
self.convs.append(SAGEConv(in_channels, hidden_channels))
for _ in range(num_layers - 2):
self.convs.append(SAGEConv(hidden_channels, hidden_channels))
self.convs.append(SAGEConv(hidden_channels, out_channels))
def forward(self, x, adj_t, *args):
for conv, history in zip(self.convs[:-1], self.histories):
x = conv(x, adj_t).relu_()
x = self.push_and_pull(history, x, *args)
return self.convs[-1](x, adj_t)
perm, ptr = metis(data.adj_t, num_parts=40, log=True)
data = permute(data, perm, log=True)
loader = SubgraphLoader(data, ptr, batch_size=10, shuffle=True)
model = GNN(...)
for batch, *args in loader:
out = model(batch.x, batch.adj_t, *args)A detailed description of ScalableGNN can be found in its implementation.
Requirements
- Install PyTorch >= 1.7.0
- Install PyTorch Geometric >= 1.7.0:
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html
pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html
pip install torch-geometricwhere ${TORCH} should be replaced by either 1.7.0 or 1.8.0, and ${CUDA} should be replaced by either cpu, cu92, cu101, cu102, cu110 or cu111, depending on your PyTorch installation.
Installation
pip install git+https://github.com/rusty1s/pyg_autoscale.gitor
python setup.py installProject Structure
torch_geometric_autoscale/contains the source code of PyGASexamples/contains examples to demonstrate how to apply GAS in practicesmall_benchmark/includes experiments to evaluate GAS performance on small-scale graphslarge_benchmark/includes experiments to evaluate GAS performance on large-scale graphs
We use Hydra to manage hyperparameter configurations.
Cite
Please cite our paper if you use this code in your own work:
@inproceedings{Fey/etal/2021,
title={{GNNAutoScale}: Scalable and Expressive Graph Neural Networks via Historical Embeddings},
author={Fey, M. and Lenssen, J. E. and Weichert, F. and Leskovec, J.},
booktitle={International Conference on Machine Learning (ICML)},
year={2021},
}