kafkajs-async-retry
![]()
![]()
This module handles retries and dead-lettering for messages from a Kafka topic without blocking the processing of subsequent messages. It is intended to be used in conjunction with KafkaJS.
Getting Started
Prerequisites
Your project should have a dependency on KafkaJS, which is listed as a peer dependency of this module. This module has no other runtime dependencies.
Installation
npm install --save kafkajs-async-retry
# or using yarn
yarn add kafkajs-async-retryCompatibility Requirements
- You must be using a version of Kafka that supports message headers (
>= v0.11.0.0). - You must be using a version of KafkaJS that provides a
pausecallback function to theeachMessage/eachBatchhandler functions (>= 2.1.0)
Kafka Setup
Depending on how you want to retry failed messages, you must create topics to store the retried messages in addition to the primary topics that your application is already using.
- Each consumer group must have a topic named
${consumerGroup}-dlq. This topic represents the dead-letter queue of messages that have failed after multiple retry attempts. - Each consumer group must have a series of topics to hold the messages to retry.
The names of these topics depend on which retry topic naming strategy you use, which you set with the
retryTopicNamingparameter.- If you set the
retryTopicNamingparameter toRetryTopicNaming.ATTEMPT_BASED(the default), you must create a series of topics for each consumer group that are numbered according to the retry attempt. For example, if you want to retry failed messages three more times in addition to the initial attempt, create topics named${consumerGroup}-retry-1,${consumerGroup}-retry-2, and${consumerGroup}-retry-3. You can configure the delay between retry attempts with theretryDelaysparameter. - If you set the
retryTopicNamingparameter toRetryTopicNaming.DELAY_BASED, you must create a series of topics for each consumer group that represent the amount of time to wait between retry attempts. For example, if you want to wait 5 seconds for the first two retry attempts and 60 seconds for the third, create topics named${consumerGroup}-retry-5sand${consumerGroup}-retry-60s. You can configure the total number of retry attempts with themaxRetriesparameter.
- If you set the
Remember, each of the topics used for facilitating retries should also have appropriate retention configurations that don't conflict with your retry times. For example, if your retry policy requires messages to be persisted for 24 hours before a retry is attempted, your retention policy should allow plenty of leeway for the retry message to be picked up.
For more information on configuring retries, see Retry Topic Naming Strategies.
Example Usage
To use this module, create an AsyncRetryHelper object with the parameters that specify the retry delay, retry strategy, and number of retries, as in this example:
//Note: The producer should already be connected to the Kafka cluster
import AsyncRetryHelper, { RetryTopicNaming } from "kafkajs-async-retry";
const asyncRetryHelper = new AsyncRetryHelper({
producer,
groupId: "test-group",
retryTopicNaming: RetryTopicNaming.ATTEMPT_BASED,
retryDelays: [5, 30, 60],
maxRetries: 3,
});You'll then need to ensure that your consumer is subscribed to the appropriate retry topics.
consumer.subscribe({
topics: [asyncRetryHelper.retryTopicPattern],
fromBeginning: true,
});Finally, use the eachMessage() or eachBatch() helpers to process the messages.
To indicate that the message failed to process and send it back to the retry topics, throw an exception.
await consumer.run({
eachMessage: asyncRetryHelper.eachMessage(
async ({ topic, originalTopic, message, previousAttempts }) => {
if (previousAttempts > 0) {
console.log(`Retrying message from topic ${originalTopic}`);
}
// do something with the message (exceptions will be caught and the
// message will be sent to the appropriate retry or dead-letter topic)
processMessage(message);
},
),
});Here's a complete example:
const { Kafka } = require("kafkajs");
const AsyncRetryHelper,
{ RetryTopicNaming } = require("kafkajs-async-retry");
const kafka = new Kafka({
clientId: "my-app",
brokers: ["kafka1:9092", "kafka2:9092"],
});
const producer = kafka.producer();
await producer.connect();
const consumer = kafka.consumer({ groupId: "test-group" });
const asyncRetryHelper = new AsyncRetryHelper({
producer,
groupId: "test-group",
retryTopicNaming: RetryTopicNaming.ATTEMPT_BASED,
retryDelays: [5, 30, 60],
maxRetries: 3,
});
// set up the consumer
await consumer.connect();
await consumer.subscribe({ topics: ["test-topic"], fromBeginning: true });
// using a pattern here instead of an explicit list of topics will ensure
// messages from all retry topics are picked up for processing (even for
// retry topics that are no longer in use which may be the case if retry
// times or retry strategies are changed)
await consumer.subscribe({
topics: [asyncRetryHelper.retryTopicPattern],
fromBeginning: true,
});
// if you'd rather subscribe to only retry topics that are currently in
// use, you can use the following:
await consumer.subscribe({
topics: asyncRetryHelper.retryTopics,
fromBeginning: true,
});
// consume messages one at a time
await consumer.run({
eachMessage: asyncRetryHelper.eachMessage(
async ({ topic, originalTopic, message, previousAttempts }) => {
if (previousAttempts > 0) {
console.log(`Retrying message from topic ${originalTopic}`);
}
// do something with the message (exceptions will be caught and the
// message will be sent to the appropriate retry or dead-letter topic)
processMessage(message);
},
),
});
// or, consume messages as a batch (more advanced, requires more
// implementation on your part)
await consumer.run({
eachBatch: asyncRetryHelper.eachBatch(
async ({ messageFailureHandler, asyncRetryMessageDetails, ...payload }) => {
payload.batch.messages.forEach((message) => {
if (asyncRetryMessageDetails.previousAttempts > 0) {
console.log(
`Retrying message from topic ${asyncRetryMessageDetails.originalTopic}`,
);
}
try {
// do something with message
} catch (err) {
messageFailureHandler(err, message);
}
});
},
),
});
// you can register event handlers for a couple relevant events if
// you'd like to take any action when messages are being queued for retry
// or dead-lettering. These events are fired _after_ the message has been sent
// to the relevant topic.
asyncRetryHelper.on("retry", ({ message, error }) => {
// log info about message/error here
});
asyncRetryHelper.on("dead-letter", ({ message, error }) => {
// log info about message/error here
});Overview and Methodology
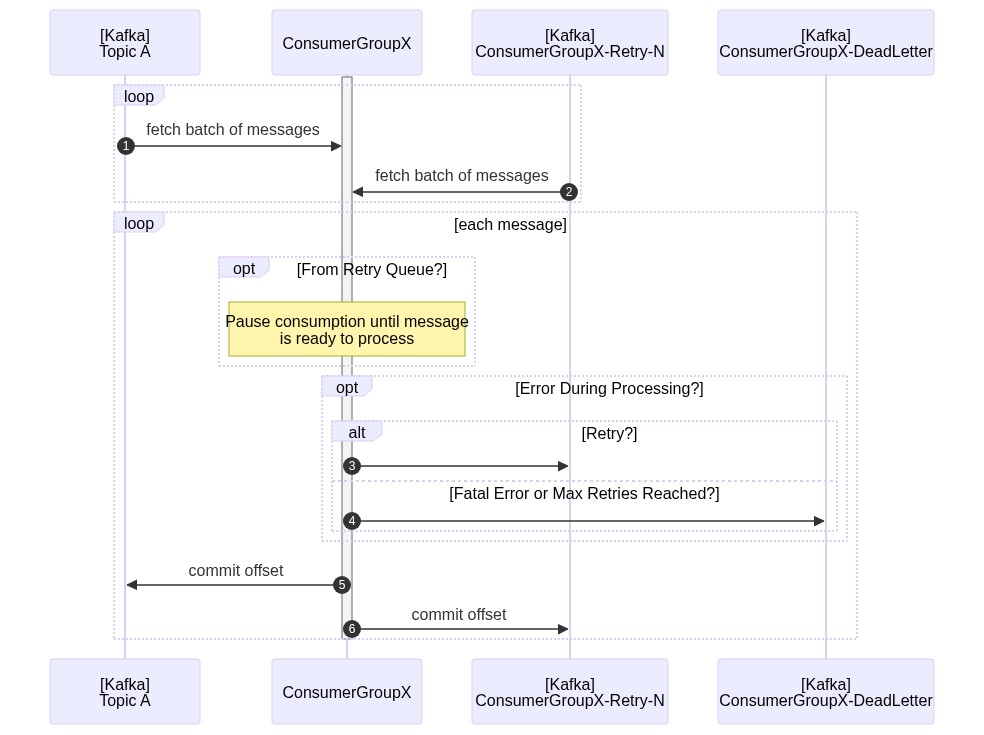
The approach used here has been explained in detail in various places including a helpful blog post from Uber Engineering. To summarize: when a message cannot be processed successfully, it is published to a different "retry" topic. The current offset on the original topic/partition is advanced as if the message was successfully processed so other messages can be processed without delay. Messages from the "retry" topics are then processed after a configurable delay. If a message continues to fail beyond a configurable maximum number of attempts, the message is published to a "dead letter" topic for manual inspection. Here's a sequence diagram demonstrating the process:
Retry Topic Naming Strategies
The naming strategy that you choose determines the topics that you must create in Kafka.
Topics based on the number of attempts
By default, the kafkajs-async-retry module will publish a failed message to a retry topic based on the number of previous attempts.
For example, if you want your consumer group to retry messages three times, you need three topics (in addition to the primary topics and the dead-letter topic mentioned above): ${consumerGroup}-retry-1, ${consumerGroup}-retry-2, and ${consumerGroup}-retry-3.
This retry strategy has these advantages:
- You can set the retry delay dynamically in the code without having to create any new topics. However, if you change the retry delay, existing messages in the retry topic keep the delay time that was in effect when they were published to the retry topic.
- Based on the number of messages in each topic, you can see how many retries are required before messages are processed successfully. If you are monitoring for offset lag on these retry topics, you must take the configured delay into account since each message being retried waits for a certain amount of time before the retry consumer picks it up.
A downside of this strategy is that if you want to increase the number of retries, you must create additional topics.
To use this retry strategy, use the RetryTopicNaming.ATTEMPT_BASED retryTopicNaming configuration in the AsyncRetryHelper constructor.
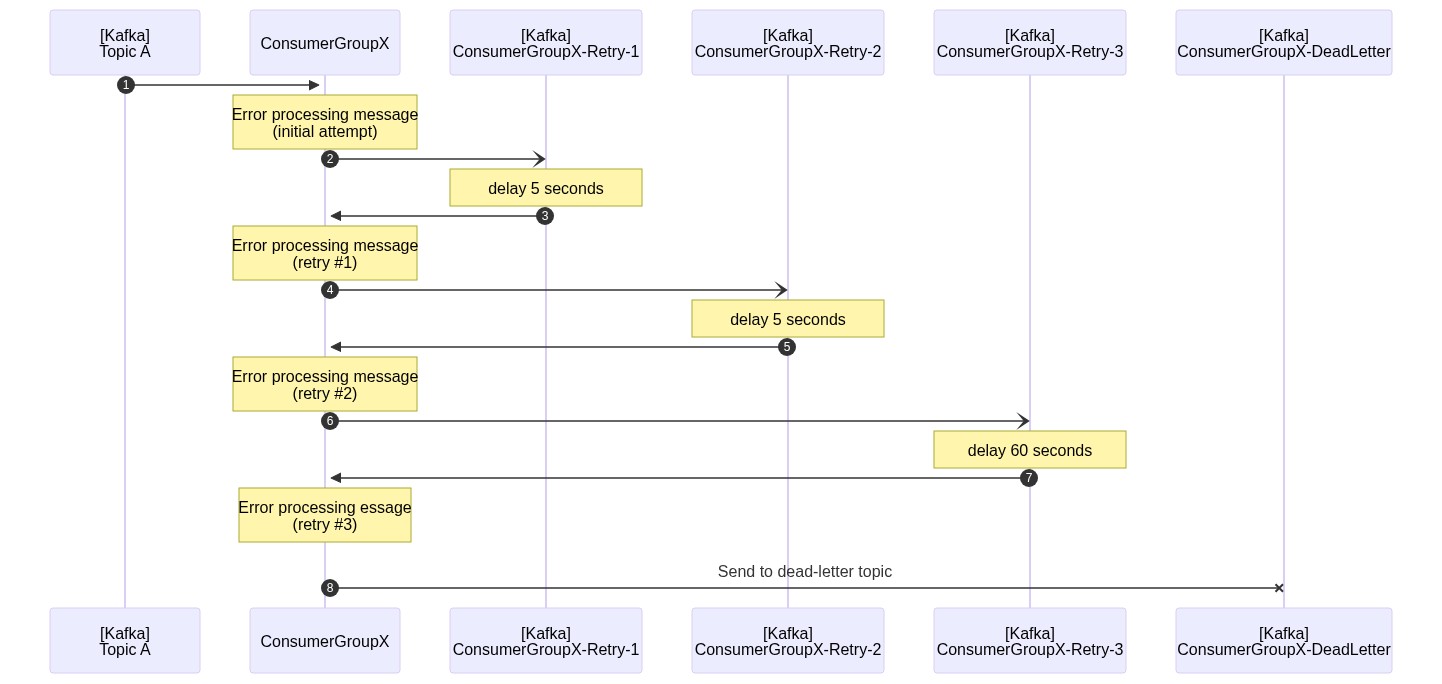
Here's a diagram of the message flow using this retry strategy. This example uses a maximum of three retries with configured wait times of 5 seconds on the first two retries and a 60-second delay on the final attempt:
Topics based on the configured delay
Another naming strategy is to name retry topics based on the number of seconds to delay between attempts. This module puts the messages into different topics depending on how long to wait before retrying them.
For example, if you want to retry messages every 5 seconds, you can create a topic named ${consumerGroup}-retry-5s and send messages to that topic repeatedly until they succeed or reach the maximum number of attempts.
If you have various delays based on which attempt is, you need a topic for each distinct configured delay.
Note the s at the end of the topic name, which indicates that it is the number of seconds to wait and not the number of retries as used in the prior naming strategy.
The advantage of this strategy is that you can retry messages many times without having to create many topics, as long as the length of the delay stays the same. If you want to always wait the same amount of time between each attempt, you need only one retry topic and the dead letter topic.
However, if you want to change the length of the delays, you must create additional topics and ensure that any remaining messages from the existing topics are processed. This strategy also prevents you from easily judging how many messages are reaching different levels of retry, because you can't tell how many times a message has been tried based on which topic it's in.
To use this retry strategy, use the RetryTopicNaming.DELAY_BASED retryTopicNaming configuration in the AsyncRetryHelper constructor.
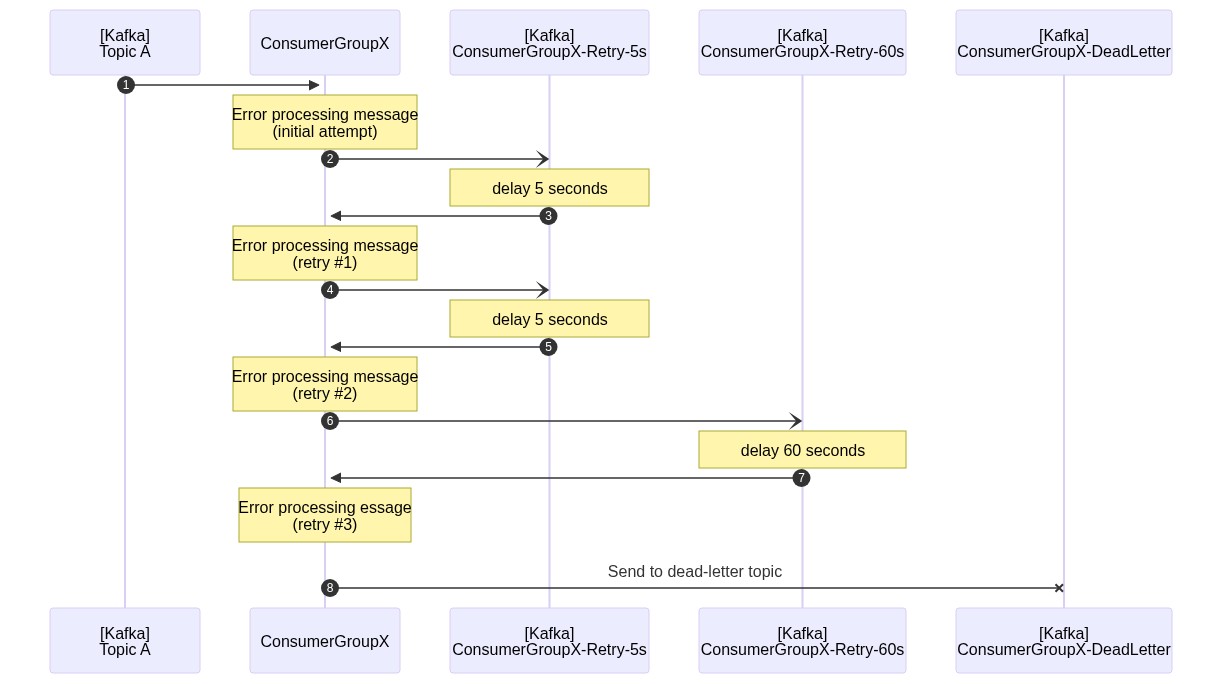
Here's a sequence diagram of the various topics needing when using a DELAY_BASED naming strategy with the retryDelays parameter set to [5, 5, 60]:
API
AsyncRetryHelper (constructor)
This is the default export and is the primary entry point for all functionality provided by this module. It accepts a single argument, an object with the following properties:
| Property | Type | Description |
|---|---|---|
groupId |
string |
Required. The consumer group id that this helper is facilitating retries for. |
producer |
kafkajs.Producer |
Required. The producer instance to use when publishing messages to retry topics. The producer should already be connected to the Kafka cluster. |
maxRetries |
number |
Default: 5. The maximum number of retries for a given message |
maxWaitTime |
number |
Default: 3000. The maximum amount of time (in milliseconds) that an eachMessage handler will wait before proceeding if the retry message is not yet ready to be processed (due to the configured delay). If the message is not going to be ready within this number of milliseconds, consumption from that topic/partition is paused. Note: this feature is not used at all when processing messages using the eachBatch callback handler. This value should be less than your sessionTimeout consumer configuration to avoid session timeouts. |
retryDelays |
number[] |
Default: [5]. The number of seconds to wait before attempting another retry. If the number of retries exceeds the configured number of retry delays, the final retry delay value is used for each remaining retry attempt. |
retryTopicNaming |
RetryTopicNaming |
Default: RetryTopicNaming.ATTEMPT_BASED. The strategy to use when naming retry topics (as discussed above). |
AsyncRetryHelper#eachMessage
This method provides a simple wrapper around the standard eachMessage handler function that you would typically pass to KafkaJS's Consumer#run method.
It extends the data provided to the handler function with the following properties:
| Property | Type | Description |
|---|---|---|
isRetry |
boolean |
Indicates whether this attempt to process the message is a retry or the initial attempt. |
originalTopic |
string |
The topic that the message was originally published to. In the case of a message that is being attempted for the first time, that will match the standard topic property that KafkaJS passes through. |
previousAttempts |
number |
The number of previous attempts that have been made for this message. On the first attempt (before any retries) the value is 0. |
processTime |
Date |
The earliest time the message should be processed (should always be in the past since the AsyncRetryHelper handles pausing processing if messages are not ready) |
If your message handler throws an exception, the wrapper catches the exception and sends the message to the appropriate retry topic or the dead-letter queue, if the maximum number of attempts has been exceeded.
To send a message directly to the dead letter topic and avoid any subsequent retries, throw a DeadLetter exception, which is exported by this module.
AsyncRetryHelper#eachBatch
Very similar to the above, this method provides a wrapper around the standard eachBatch handler function that you would typically pass to KafkaJS's Consumer#run method. It extends the data provided to the handler function with the following callback methods:
| Function Name | Arguments | Description |
|---|---|---|
asyncRetryMessageDetails |
kafkajs.KafkaMessage |
Returns an AsyncRetryMessageDetails object with properties as described above under the eachMessage documentation |
messageFailureHandler |
Error, kafkajs.KafkaMessage |
Handles publishing the message to the appropriate retry (or dead-letter) topic; this method is asynchronous and should be await'd |
To send a message directly to the dead letter topic and avoid any subsequent retries, provide a DeadLetter exception to the messageFailureHandler callback function.
🚨 Important 🚨
Like the KafkaJS docs mention, using
eachBatchdirectly is considered a "more advanced use case" and it is recommended that you use theeachMessageapproach unless there is a specific reason that mode of processing is not workable. While the implementation inside this module is a lot more complex for theeachBatchprocessing model thaneachMessage, the primary difference exposed to the consumer of this functionality is that instead of simply allowing exceptions to bubble up to theeachMessagewrapper function, themessageFailureHandlercallback function must be used. Also, when processing retries of a message usingeachBatch, some of the batch metadata provided to theeachBatchhandler function will almost certainly be incorrect since the batch of messages from a retry topic may be split since some messages may not ready to be retried quite yet. When that happens, no attempt is made to keep the various attributes of thebatchobject (i.e.offsetLag(),offsetLagLow(),firstOffset()andlastOffset()), in sync with the actual batch of messages that are being passed to youreachBatchhandler.
AsyncRetryHelper#on
This class does emit two (in-process) events that may be useful for visibility into your message retry processing: AsyncRetryEvent.RETRY and AsyncRetryEvent.DEAD_LETTER.
In both cases, the event payload consists of a single object with the following properties:
| Property | Type | Description |
|---|---|---|
message |
KafkaMessage |
The same value as what is provided to the eachMessage or eachBatch callback |
details |
AsyncRetryMessageDetails |
Provides information as described above under the [eachMessage(#asyncretryhelpereachmessage) documentation |
error |
Error (or sub-class) |
The most recent error object that is resulting in the message being retried or dead-letter'd |
topic |
string |
The destination topic for the current retry attempt or the dead-letter queue as applicable |
These events are emitted after the message has been published to the retry or dead-letter topic.
Keep in mind that, per the EventEmitter docs, event handlers will be processed synchronously in the order they are registered.
Other Exports
AsyncRetryEvents (enum)
Provides the names of the different events that are emitted by the AsyncRetryHelper class as described above.
DeadLetter (sub-class of Error)
This exception is used to indicate that a message should be "dead-lettered" (i.e. not retried).
If you throw this exception in an eachMessage handler or pass it to the messageFailureHandler callback (when using eachBatch processing mode), the message will be delivered to the dead-letter topic.
The DeadLetter constructor takes a single argument, a string that indicates the reason the message is being dead-lettered.
RetryTopicNaming (enum)
Provides two enum values (as described in Retry Topic Naming Strategies) that can be provided to the AsyncRetryHelper constructor to configure the naming strategy used for retry topics.