datasette-graphql


![]()
![]()
Datasette plugin providing an automatic GraphQL API for your SQLite databases
Read more about this project: GraphQL in Datasette with the new datasette-graphql plugin
Try out a live demo at datasette-graphql-demo.datasette.io/graphql
- Installation
- Configuration
- Usage
- The graphql() template function
- Adding custom fields with plugins
- Development
Installation
Install this plugin in the same environment as Datasette.
$ datasette install datasette-graphqlConfiguration
By default this plugin adds the GraphQL API at /graphql. You can configure a different path using the path plugin setting, for example by adding this to metadata.json:
{
"plugins": {
"datasette-graphql": {
"path": "/-/graphql"
}
}
}This will set the GraphQL API to live at /-/graphql instead.
Usage
This plugin sets up /graphql as a GraphQL endpoint for the first attached database.
If you have multiple attached databases each will get its own endpoint at /graphql/name_of_database.
The automatically generated GraphQL schema is available at /graphql/name_of_database.graphql - here's an example.
Querying for tables and columns
Individual tables (and SQL views) can be queried like this:
{
repos {
nodes {
id
full_name
description_
}
}
}In this example query the underlying database table is called repos and its columns include id, full_name and description. Since description is a reserved word the query needs to ask for description_ instead.
Fetching a single record
If you only want to fetch a single record - for example if you want to fetch a row by its primary key - you can use the tablename_row field:
{
repos_row(id: 107914493) {
id
full_name
description_
}
}The tablename_row field accepts the primary key column (or columns) as arguments. It also supports the same filter:, search:, sort: and sort_desc: arguments as the tablename field, described below.
Accessing nested objects
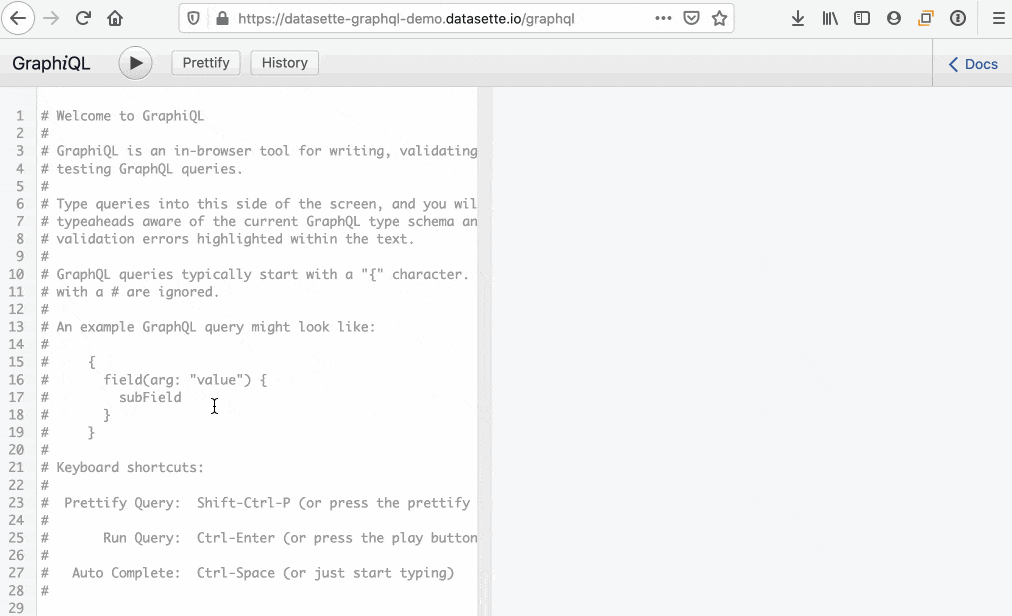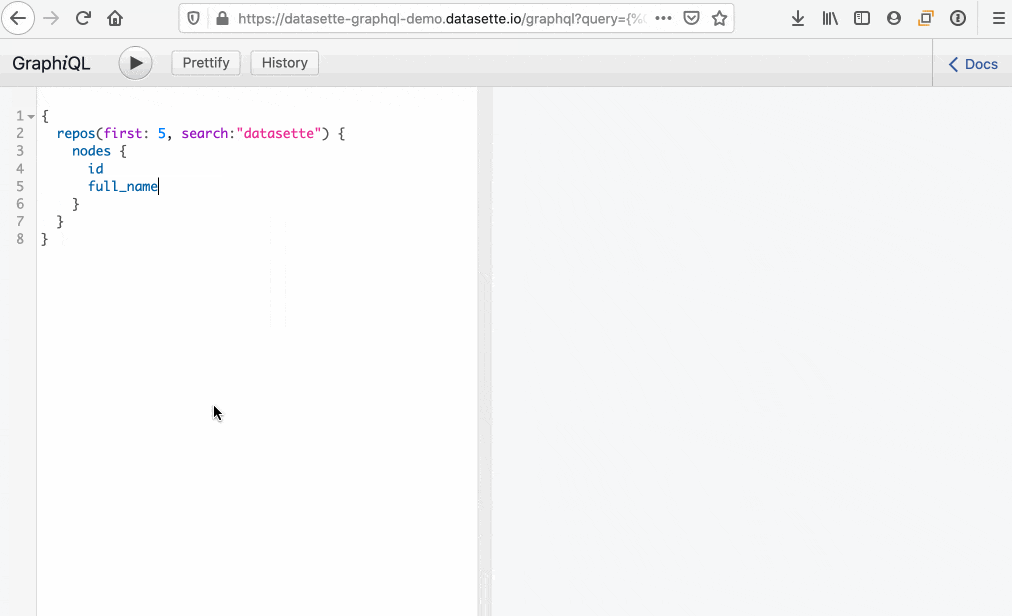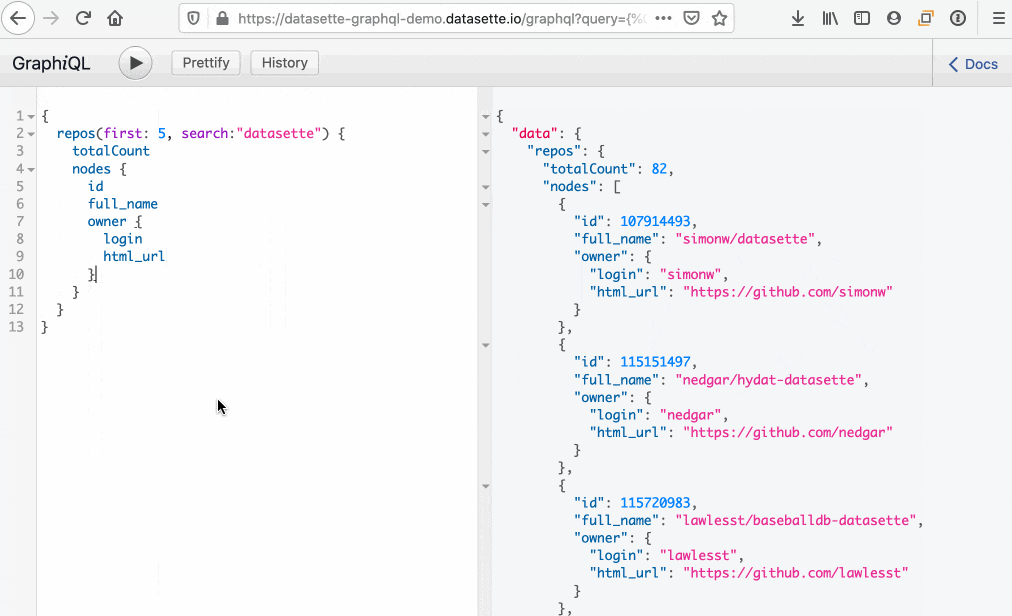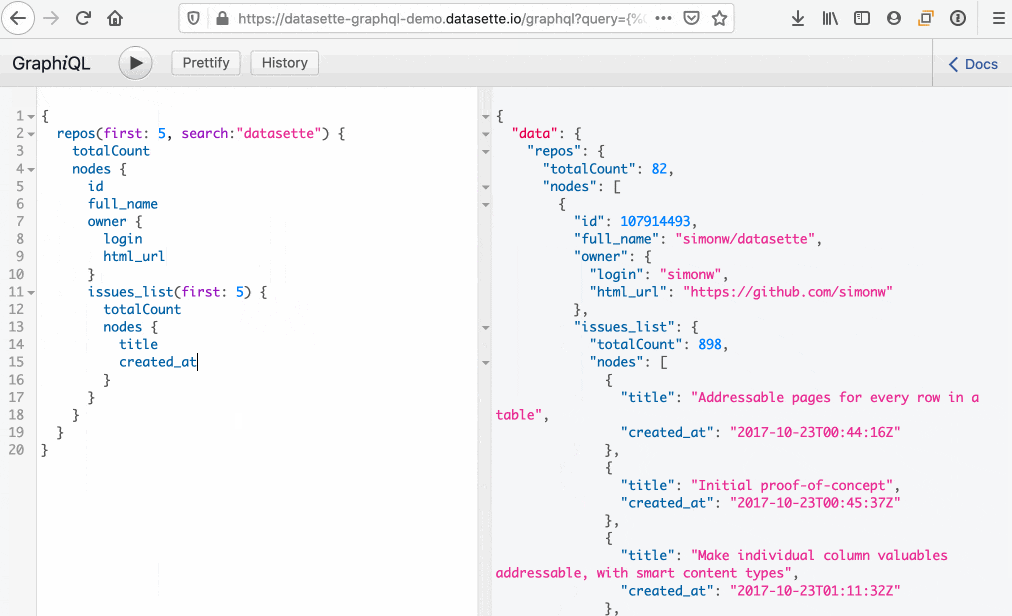
If a column is a foreign key to another table, you can request columns from the table pointed to by that foreign key using a nested query like this:
{
repos {
nodes {
id
full_name
owner {
id
login
}
}
}
}Accessing related objects
If another table has a foreign key back to the table you are accessing, you can fetch rows from that related table.
Consider a users table which is related to repos - a repo has a foreign key back to the user that owns the repository. The users object type will have a repos_by_owner_list field which can be used to access those related repos:
{
users(first: 1, search: "simonw") {
nodes {
name
repos_by_owner_list(first: 5) {
totalCount
nodes {
full_name
}
}
}
}
}Filtering tables
You can filter the rows returned for a specific table using the filter: argument. This accepts a filter object mapping columns to operations. For example, to return just repositories with the Apache 2 license and more than 10 stars:
{
repos(filter: {license: {eq: "apache-2.0"}, stargazers_count: {gt: 10}}) {
nodes {
full_name
stargazers_count
license {
key
}
}
}
}See table filters examples for more operations, and column filter arguments in the Datasette documentation for details of how those operations work.
These same filters can be used on nested relationships, like so:
{
users_row(id: 9599) {
name
repos_by_owner_list(filter: {name: {startswith: "datasette-"}}) {
totalCount
nodes {
full_name
}
}
}
}The where: argument can be used as an alternative to filter: when the thing you are expressing is too complex to be modeled using a filter expression. It accepts a string fragment of SQL that will be included in the WHERE clause of the SQL query.
{
repos(where: "name='sqlite-utils' or name like 'datasette-%'") {
totalCount
nodes {
full_name
}
}
}Sorting
You can set a sort order for results from a table using the sort: or sort_desc: arguments. The value for this argument should be the name of the column you wish to sort (or sort-descending) by.
{
repos(sort_desc: stargazers_count) {
nodes {
full_name
stargazers_count
}
}
}Pagination
By default the first 10 rows will be returned. You can control this using the first: argument.
{
repos(first: 20) {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
full_name
stargazers_count
license {
key
}
}
}
}The totalCount field returns the total number of records that match the query.
Requesting the pageInfo.endCursor field provides you with the value you need to request the next page. You can pass this to the after: argument to request the next page.
{
repos(first: 20, after: "134874019") {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
full_name
stargazers_count
license {
key
}
}
}
}The hasNextPage field tells you if there are any more records.
Search
If a table has been configured to use SQLite full-text search you can execute searches against it using the search: argument:
{
repos(search: "datasette") {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
full_name
description_
}
}
}The sqlite-utils Python library and CLI tool can be used to add full-text search to an existing database table.
Columns containing JSON strings
If your table has a column that contains data encoded as JSON, datasette-graphql will make that column available as an encoded JSON string. Clients calling your API will need to parse the string as JSON in order to access the data.
You can return the data as a nested structure by configuring that column to be treated as a JSON column. The plugin configuration for that in metadata.json looks like this:
{
"databases": {
"test": {
"tables": {
"repos": {
"plugins": {
"datasette-graphql": {
"json_columns": [
"tags"
]
}
}
}
}
}
}
}Auto camelCase
The names of your columns and tables default to being matched by their representations in GraphQL.
If you have tables with names_like_this you may want to work with them in GraphQL using namesLikeThis, for consistency with GraphQL and JavaScript conventions.
You can turn on automatic camelCase using the "auto_camelcase" plugin configuration setting in metadata.json, like this:
{
"plugins": {
"datasette-graphql": {
"auto_camelcase": true
}
}
}CORS
This plugin obeys the --cors option passed to the datasette command-line tool. If you pass --cors it adds the following CORS HTTP headers to allow JavaScript running on other domains to access the GraphQL API:
access-control-allow-headers: content-type
access-control-allow-method: POST
access-control-allow-origin: *Execution limits
The plugin implements two limits by default:
- The total time spent executing all of the underlying SQL queries that make up the GraphQL execution must not exceed 1000ms (one second)
- The total number of SQL table queries executed as a result of nested GraphQL fields must not exceed 100
These limits can be customized using the num_queries_limit and time_limit_ms plugin configuration settings, for example in metadata.json:
{
"plugins": {
"datasette-graphql": {
"num_queries_limit": 200,
"time_limit_ms": 5000
}
}
}Setting these to 0 will disable the limit checks entirely.
The graphql() template function
The plugin also makes a Jinja template function available called graphql(). You can use that function in your Datasette custom templates like so:
{% set users = graphql("""
{
users {
nodes {
name
points
score
}
}
}
""")["users"] %}
{% for user in users.nodes %}
<p>{{ user.name }} - points: {{ user.points }}, score = {{ user.score }}</p>
{% endfor %}The function executes a GraphQL query against the generated schema and returns the results. You can assign those results to a variable in your template and then loop through and display them.
By default the query will be run against the first attached database. You can use the optional second argument to the function to specify a different database - for example, to run against an attached github.db database you would do this:
{% set user = graphql("""
{
users_row(id:9599) {
name
login
avatar_url
}
}
""", "github")["users_row"] %}
<h1>Hello, {{ user.name }}</h1>You can use GraphQL variables in these template calls by passing them to the variables= argument:
{% set user = graphql("""
query ($id: Int) {
users_row(id: $id) {
name
login
avatar_url
}
}
""", database="github", variables={"id": 9599})["users_row"] %}
<h1>Hello, {{ user.name }}</h1>Adding custom fields with plugins
datasette-graphql adds a new plugin hook to Datasette which can be used to add custom fields to your GraphQL schema.
The plugin hook looks like this:
@hookimpl
def graphql_extra_fields(datasette, database):
"A list of (name, field_type) tuples to include in the GraphQL schema"You can use this hook to return a list of tuples describing additional fields that should be exposed in your schema. Each tuple should consist of a string naming the new field, plus a Graphene Field object that specifies the schema and provides a resolver function.
This example implementation uses pkg_resources to return a list of currently installed Python packages:
import graphene
from datasette import hookimpl
import pkg_resources
@hookimpl
def graphql_extra_fields():
class Package(graphene.ObjectType):
"An installed package"
name = graphene.String()
version = graphene.String()
def resolve_packages(root, info):
return [
{"name": d.project_name, "version": d.version}
for d in pkg_resources.working_set
]
return [
(
"packages",
graphene.Field(
graphene.List(Package),
description="List of installed packages",
resolver=resolve_packages,
),
),
]With this plugin installed, the following GraphQL query can be used to retrieve a list of installed packages:
{
packages {
name
version
}
}Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd datasette-graphql
python3 -mvenv venv
source venv/bin/activateOr if you are using pipenv:
pipenv shellNow install the dependencies and tests:
pip install -e '.[test]'To run the tests:
pytest