Naemon Gearman Module
What is Mod-Gearman
http://labs.consol.de/nagios/mod-gearman[Mod_Gearman] is an easy way of distributing active Naemon checks across your network and increasing Naemon scalability. Mod-Gearman can even help to reduce the load on a single Naemon host, because its much smaller and more efficient in executing checks.
- Mod-Gearman 4.x works with https://www.naemon.io[Naemon Core]
It consists of three parts:
- There is a NEB module which resides in the Naemon core and adds servicechecks, hostchecks and eventhandler to a Gearman queue.
- The counterpart is one or more worker clients executing the checks. Worker can be configured to only run checks for specific host- or servicegroups. There is a (deprecated) worker included. The new worker is here: https://github.com/ConSol/mod-gearman-worker-go/[mod-gearman-worker-go].
- And you need at least one http://gearman.org[Gearman Job Server] running.
- See the <<common-scenarios,common scenarios>> for some examples.
Presentations
- http://mod-gearman.org/slides/Mod-Gearman-2012-10-18.pdf[Monitoring Conference 2012 in Nürnberg]
- http://mod-gearman.org/slides/Mod-Gearman-2011-05-24.pdf[Nagios Workshop 2011 in Hannover]
Features
- Reduce load of your central Naemon machine
- Make Naemon scalable up to thousands of checks per second
- Easy distributed setups without configuration overhead
- Real loadbalancing across all workers
- Real failover for redundant workers
- Embedded Perl support for very fast execution of perl scripts
- Fast transport of passive check results with included tools like send_gearman and send_multi
Download
- Latest stable release http://www.mod-gearman.org/download/v3.0.5/src/mod_gearman-3.0.5.tar.gz[version 3.0.5], released Jul 10 2017
- Mod Gearman is available for download at: http://mod-gearman.org/download.html
- Source is available on GitHub: http://github.com/sni/mod_gearman
- Older versions are available in the <<_archive,download archive>>.
- Mod-Gearman is also included in http://omdistro.org[OMD].
- Debian users should use the http://packages.debian.org/source/wheezy/mod-gearman[official packages]
- SLES/RHEL/Centos users should use the http://mod-gearman.org/download/[prebuild packages]
- Debian/Ubuntu users might also want to check out the http://mod-gearman.org/download/[unoffical packages]
Support
- Professional support and consulting is available via http://www.consol.de/open-source-monitoring/support/[www.consol.de]
- https://groups.google.com/group/mod_gearman[google groups mailinglist]
- http://www.monitoring-portal.org[german monitoring portal]
- Mod-Gearman has been succesfully tested with latest Naemon. See <<supported-dependencies,Supported Dependencies>> for details.
- There are no known bugs at the moment. Let me know if you find one.
Changelog
The changelog is available on https://github.com/sni/mod_gearman/blob/master/Changes[github].
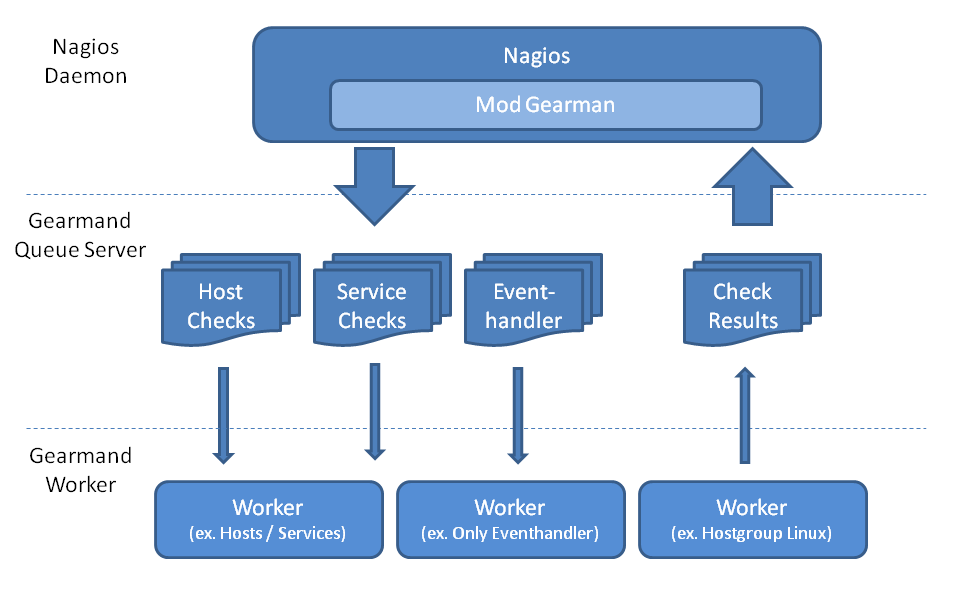
How does it work
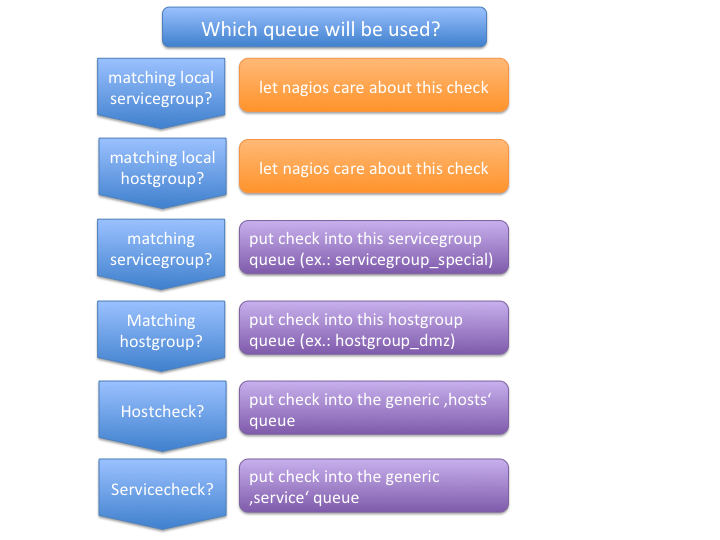
When the Mod-Gearman broker module is loaded, it intercepts all servicechecks, hostchecks and the eventhandler events. Eventhandler are then sent to a generic 'eventhandler' queue. Checks for hosts which are in one of the specified hostgroups, are sent into a seperate hostgroup queue. All non matching hosts are sent to a generic 'hosts' queue. Checks for services are first checked against the list of servicegroups, then against the hostgroups and if none matches they will be sent into a generic 'service' queue. The NEB module starts a single thread, which monitors the 'check_results' where all results come in.
++++
 ++++
++++
A simple example queue would look like:
+---------------+------------------+--------------+--------------+ | Queue Name | Worker Available | Jobs Waiting | Jobs Running | +---------------+------------------+--------------+--------------+ | check_results | 1 | 0 | 0 | | eventhandler | 50 | 0 | 0 | | host | 50 | 0 | 1 | | service | 50 | 0 | 13 | +---------------+------------------+--------------+--------------+
There is one queue for the results and two for the checks plus the eventhandler queue.
The workflow is simple:
- Naemon wants to execute a service check.
- The check is intercepted by the Mod-Gearman neb module.
- Mod-Gearman puts the job into the 'service' queue.
- A worker grabs the job and puts back the result into the 'check_results' queue
- Mod-Gearman grabs the result job and puts back the result onto the check result list
- The Naemon reaper reads all checks from the result list and updates hosts and services
You can set some host or servicegroups for special worker. This example uses a seperate hostgroup for Japan and a seperate servicegroup for resource intensive selenium checks.
It would look like this:
+-----------------------+------------------+--------------+--------------+ | Queue Name | Worker Available | Jobs Waiting | Jobs Running | +-----------------------+------------------+--------------+--------------+ | check_results | 1 | 0 | 0 | | eventhandler | 50 | 0 | 0 | | host | 50 | 0 | 1 | | hostgroup_japan | 3 | 1 | 3 | | service | 50 | 0 | 13 | | servicegroup_selenium | 2 | 0 | 2 | +-----------------------+------------------+--------------+--------------+
You still have the generic queues and in addition there are two queues for the specific groups.
The worker processes will take jobs from the queues and put the result back into the check_result queue which will then be taken back by the neb module and put back into the Naemon core. A worker can work on one or more queues. So you could start a worker which only handles the 'hostgroup_japan' group. One worker for the 'selenium' checks and one worker which covers the other queues. There can be more than one worker on each queue to share the load.
++++
 ++++
++++
Common Scenarios
Load Balancing
++++
<a title="Load Balancing" rel="lightbox[mod_gm]" href="http://labs.consol.de/nagios/mod-gearman/sample_load_balancing.png"><img src="http://labs.consol.de/nagios/mod-gearman/sample_load_balancing.png" alt="Load Balancing" width="300" height="125" style="float:none" /></a>
++++
The easiest variant is a simple load balancing. For example if your
single Naemon box just cannot handle the load, you could just add a
worker in the same network (or even on the same host) to reduce your
load on the Naemon box. Therefor we just enable hosts, services and
eventhandler on the server and the worker.
Pro:
* reduced load on your monitoring box
Contra:
* no failover
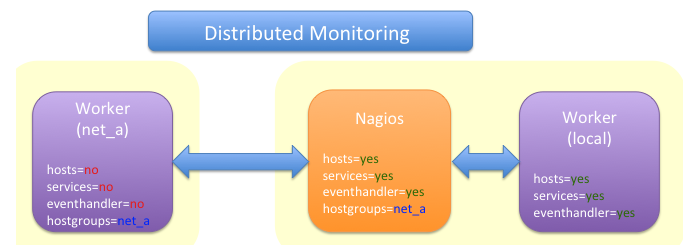
Distributed Monitoring++++
 ++++
++++
If your checks have to be run from different network segments, then you can use the hostgroups (or servicegroups) to define a hostgroup for specific worker. The general hosts and services queue is disabled for this worker and just the hosts and services from the given hostgroup will be processed.
Pro:
- reduced load on your monitoring box
- ability to access remote networks
Contra:
- no failover
Distributed Monitoring with Load Balancing
++++
<a title="Distributed Monitoring with Load Balancing" rel="lightbox[mod_gm]"
href="http://labs.consol.de/nagios/mod-gearman/sample_distributed_load_balanced.png"><img
src="http://labs.consol.de/nagios/mod-gearman/sample_distributed_load_balanced.png" alt="Distributed Monitoring with Load Balancing" width="350" height="225" style="float:none" /></a>
++++
Your distributed setup could easily be extended to a load balanced
setup with just adding more worker of the same config.
Pro:
* reduced load on your monitoring box
* ability to access remote networks
* automatic failover and load balancing for worker
Contra:
* no failover for the master
NSCA Replacement++++ <a title="NSCA Replacement" rel="lightbox[mod_gm]" href="http://labs.consol.de/nagios/mod-gearman/nsca_replacement.png"><img src="http://labs.consol.de/nagios/mod-gearman/nsca_replacement.png" alt="NSCA Replacement" width="300" height="220" style="float:none" /> ++++
If you just want to replace a current NSCA solution, you could load the Mod-Gearman NEB module and disable all distribution features. You still can receive passive results by the core send via send_gearman / send_multi. Make sure you use the same encryption settings like the neb module or your core won't be able to process the results or use the 'accept_clear_results' option.
Pro:
- easy to setup in existing environments
Distributed Setup With Remote Scheduler
++++
<a title="Distributed Setup With Remote Scheduler" rel="lightbox[mod_gm]" href="http://labs.consol.de/nagios/mod-gearman/advanced_distributed.png"><img src="http://labs.consol.de/nagios/mod-gearman/advanced_distributed.png" alt="Distributed Setup With Remote Scheduler" width="360" height="270" style="float:none" /></a>
++++
In case your network is unstable or you need a gui view from the
remote location or any other reason which makes a remote core
unavoidable you may want this setup. Thist setup consists of 2
independent Mod-Gearman setups and the slave worker just send their
results to the master via the 'dup_server' option. The master
objects configuration must contain all slave services and hosts.
The configuration sync is not part of Mod-Gearman.
Pro:
* independent from network outtakes
* local view
Contra:
* more complex setup
* requires configuration sync
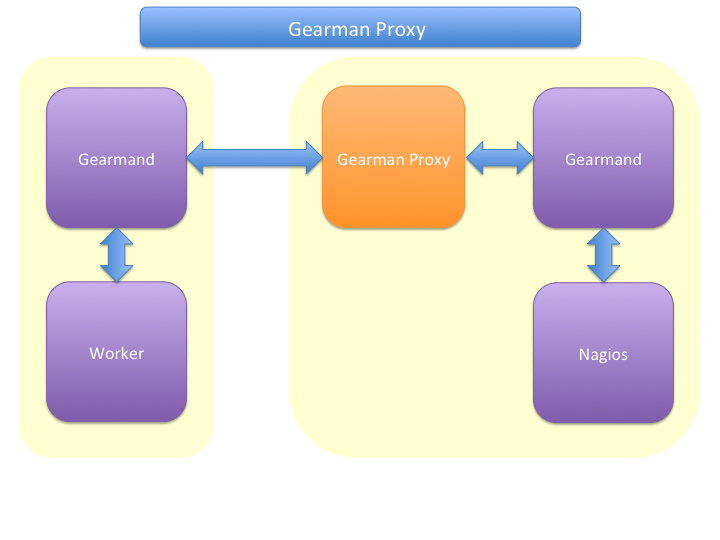
Gearman Proxy++++
 ++++
++++
Sometimes you may need to reverse the direction of the initial connection attempt. Usually the worker and the neb module open the initial connection so they need to access the gearmand port. In cases where no direct connection is possible use ssh tunnel or the Gearman proxy. The Gearman proxy just puts jobs from one gearmand into another gearmand and vice versa.
gearman_proxy.pl can be found at https://github.com/sni/gearman-proxy
Pro:
- changes direction of initial connection setup
- buffers network outages
Contra:
- two more daemon to monitor and maintain
Installation
OMD
Using OMD is propably the easiest way of installing and using
Mod-Gearman. You just have to run 'omd config' or set Mod-Gearman
to 'on'.
OMD is available for Debian, Ubuntu, Centos/Redhat and SLES.
--------------------------------------
OMD[test]:~$ omd config set MOD_GEARMAN on
--------------------------------------
NOTE: Mod-Gearman is included in http://omdistro.org[OMD] since version 0.48.
Debian / UbuntuIt is strongly recommended to use the http://packages.debian.org/source/wheezy/mod-gearman[official packages] or the http://mod-gearman.org/download/[unoffical packages] which contains Debian Squeeze and various Ubuntu packages.
Centos/Redhat
The easy and proper way is to build RPM packages. The following steps
assume a Centos 5.7. Other releases may have different versions but
should behave similar.
NOTE: use the http://mod-gearman.org/download/[prebuild packages] if
available.
Build/install Gearmand rpms
--------------------------------------
#> yum install autoconf automake libtool boost141-devel boost141-program-options
#> cd /tmp
#> wget http://launchpad.net/gearmand/trunk/0.33/+download/gearmand-0.33.tar.gz
#> tar zxf gearmand-0.33.tar.gz
#> ln -s gearmand-0.33/support/gearmand.init /tmp/gearmand.init
#> vi gearmand-0.33/support/gearmand.spec
change in line 9 and 25:
Requires: sqlite, libevent >= 1.4, boost-program-options >= 1.39
in
Requires: sqlite, libevent >= 1.4, boost141-program-options >= 1.39
#> tar cfz gearmand-0.33.tar.gz gearmand-0.33
#> LIBRARY_PATH=/usr/lib64/boost141:/usr/lib/boost141 \
LD_LIBRARY_PATH=/usr/lib64/boost141:/usr/lib/boost141 \
CPATH=/usr/include/boost141 \
rpmbuild -tb gearmand-0.33.tar.gz
#> yum --nogpgcheck install /usr/src/redhat/RPMS/*/gearmand*-0.33-1*.rpm
--------------------------------------
NOTE: The link to gearmand.init is a workaround, otherwise the build
will fail. It may not be necessary for future gearman versions.
Build/install Mod-Gearman rpms
--------------------------------------
#> wget http://mod-gearman.org/download/v1.5.2/src/mod_gearman-1.5.2.tar.gz
#> rpmbuild -tb mod_gearman-1.5.2.tar.gz
#> yum --nogpgcheck install /usr/src/redhat/RPMS/*/mod_gearman-1.5.2-1.*.rpm
--------------------------------------
Finally start and check your installation
--------------------------------------
#> /etc/init.d/gearmand start
#> /etc/init.d/mod_gearman_worker start
#> gearman_top
--------------------------------------
From SourceNOTE: source installation should be avoided if possible. Prebuild packages are way easier to maintain.
Pre Requirements:
- gcc / g++
- autoconf / automake / autoheader
- libtool
- libgearman (>= 0.14)
Download the tarball and perform the following steps:
> ./autogen.sh # only required when installing from git
> ./configure
> make
> make install
Then add the mod_gearman_naemon.o to your Naemon installation and add a broker line to your naemon.cfg:
broker_module=.../mod_gearman_naemon.o server=localhost:4730 eventhandler=yes services=yes hosts=yes config=.../module.conf
see <<_configuration,Configuration>> for details on all parameters
The next step is to start one or more worker. You may use the same configuration file as for the neb module.
./mod_gearman_worker --server=localhost:4730 --services --hosts
or use the supplied init script.
NOTE: Make sure you have started your Gearmand job server. Usually it can be started with
/usr/sbin/gearmand -t 10 -j 0
or a supplied init script. Command line arguments have change in recent gearman versions and you now should use something like:
/usr/sbin/gearmand --threads=10 --job-retries=0
Configuration
Naemon Core
A sample broker in your naemon.cfg could look like:
--------------------------------------
broker_module=/usr/local/share/naemon/mod_gearman_naemon.o keyfile=/usr/local/share/naemon/secret.txt server=localhost eventhandler=yes hosts=yes services=yes config=.../module.conf
--------------------------------------
See the following list for a detailed explanation of available
options:
Common OptionsShared options for worker and the NEB module:
config:: include config from this file. Options are the same as described here. 'include' is an alias for 'config'. +
config=/etc/naemon/mod_gm_worker.conf=====
debug:: use debug to increase the verbosity of the module. Possible values are: +
* `0` - only errors
* `1-4` - debug verbosity
* `5` - trace and all gearman related logs are going to stdout-- + Default is 0. +
debug=1====
logmode:: set way of logging. Possible values are: +
* `automatic` - logfile when a logfile is specified. stdout when
no logfile is given.
stdout for tools.
* `stdout` - just print all messages to stdout
* `syslog` - use syslog for all log events
* `file` - use logfile
* `core` - use naemon internal loging (not thread safe! Use
with care)-- + Default is automatic. +
logmode=automatic====
logfile:: Path to the logfile. +
logfile=/path/to/log.file====
server:: sets the address of your gearman job server. Can be specified more than once to add more server. Mod-Gearman uses the first server available. +
server=localhost:4730,remote_host:4730====
eventhandler:: defines if the module should distribute execution of eventhandlers. +
eventhandler=yes====
services:: defines if the module should distribute execution of service checks. +
services=yes====
hosts:: defines if the module should distribute execution of host checks. +
hosts=yes====
hostgroups:: sets a list of hostgroups which will go into seperate queues. +
hostgroups=name1,name2,name3====
servicegroups:: sets a list of servicegroups which will go into seperate queues. +
servicegroups=name1,name2,name3====
encryption::
enables or disables encryption. It is strongly advised to not disable
encryption. Anybody will be able to inject packages to your worker. Encryption
is enabled by default and you have to explicitly disable it. When using
encryption, you will either have to specify a shared password with key=... or
a keyfile with keyfile=....
Default is On.
+
encryption=yes====
key:: A shared password which will be used for encryption of data pakets. Should be at least 8 bytes long. Maximum length is 32 characters. +
key=secret====
keyfile:: The shared password will be read from this file. Use either key or keyfile. Only the first 32 characters from the first line will be used. Whitespace to the right will be trimmed. +
keyfile=/path/to/secret.file====
use_uniq_jobs:: Using uniq keys prevents the gearman queues from filling up when there is no worker. However, gearmand seems to have problems with the uniq key and sometimes jobs get stuck in the queue. Set this option to 'off' when you run into problems with stuck jobs but make sure your worker are running. Default is On.
+
use_uniq_jobs=on====
gearman_connection_timeout:: Timeout in milliseconds when connecting to gearmand daemon. Set to 0 to disable the timeout. Default is 5000.
+
gearman_connection_timeout=5000====
Server Options
Additional options for the NEB module only:
localhostgroups::
sets a list of hostgroups which will not be executed by gearman. They are just
passed through.
+
====
localhostgroups=name1,name2,name3
====
localservicegroups::
sets a list of servicegroups which will not be executed by gearman. They are
just passed through.
+
====
localservicegroups=name1,name2,name3
====
queue_custom_variable::
Can be used to define the target queue by a custom variable in
addition to host/servicegroups. When set for ex. to 'WORKER' you then
could define a '_WORKER' custom variable for your hosts and services
to directly set the worker queue. The host queue is inherited unless
overwritten by a service custom variable. Set the value of your custom
variable to 'local' to bypass Mod-Gearman (Same behaviour as in
localhostgroups/localservicegroups).
+
====
queue_custom_variable=WORKER
====
do_hostchecks::
Set this to 'no' if you want Mod-Gearman to only take care of
servicechecks. No hostchecks will be processed by Mod-Gearman. Use
this option to disable hostchecks and still have the possibility to
use hostgroups for easy configuration of your services.
If set to yes, you still have to define which hostchecks should be
processed by either using 'hosts' or the 'hostgroups' option.
Default: `yes`
+
====
do_hostchecks=yes
====
result_workers::
Enable or disable result worker thread. The default is one, but
you can set it to zero to disabled result workers, for example
if you only want to export performance data.
+
====
result_workers=0
====
perfdata::
Defines if the module should distribute perfdata to gearman.
Can be specified multiple times and accepts comma separated lists.
+
====
perfdata=yes
====
NOTE: processing of perfdata is not part of mod_gearman. You will need
additional worker for handling performance data. For example:
http://www.pnp4nagios.org[PNP4Nagios]. Performance data is just
written to the gearman queue.
perfdata_send_all::
Set 'perfdata_send_all=yes' to submit all performance data
of all hosts and services regardless of if they
have 'process_performance_data' enabled or not.
Default: `no`
+
====
perfdata_send_all=yes
====
perfdata_mode::
There will be only a single job for each host or service when putting
performance data onto the perfdata_queue in overwrite mode. In
append mode perfdata will be stored as long as there is memory
left. Setting this to 'overwrite' helps preventing the perf_data
queue from getting to big. Monitor your perfdata carefully when
using the 'append' mode.
Possible values are:
+
--
* `1` - overwrite
* `2` - append
--
+
Default is 1.
+
====
perfdata_mode=1
====
result_queue::
sets the result queue. Necessary when putting jobs from several Naemon instances
onto the same gearman queues. Default: `check_results`
+
====
result_queue=check_results_naemon1
====
orphan_host_checks::
The Mod-Gearman NEB module will submit a fake result for orphaned host
checks with a message saying there is no worker running for this
queue. Use this option to get better reporting results, otherwise your
hosts will keep their last state as long as there is no worker
running.
Default is yes.
+
====
orphan_host_checks=yes
====
orphan_service_checks::
Same like 'orphan_host_checks' but for services.
Default is yes.
+
====
orphan_service_checks=yes
====
orphan_return::
Set return code of orphaned checks.
Possible values are:
+
--
* `0` - OK
* `1` - WARNING
* `2` - CRITICAL
* `3` - UNKNOWN
--
+
Default is 2.
+
====
orphan_return=2
====
accept_clear_results::
When enabled, the NEB module will accept unencrypted results too. This
is quite useful if you have lots of passive checks and make use of
send_gearman/send_multi where you would have to spread the shared key
to all clients using these tools.
Default is no.
+
====
accept_clear_results=yes
====
latency_flatten_window::
When enabled, reschedules host/service checks if their latency is more than
one second. This value is the maximum delay in seconds applied to hosts/services.
Set to 0 or less than 0 to disable rescheduling.
Default is 30.
+
====
latency_flatten_window=30
====
Worker OptionsAdditional options for worker:
identifier:: Identifier for this worker. Will be used for the 'worker_identifier' queue for status requests. You may want to change it if you are using more than one worker on a single host. Defaults to the current hostname. +
identifier=hostname_test====
pidfile:: Path to the pidfile. +
pidfile=/path/to/pid.file====
job_timeout:: Default job timeout in seconds. Currently this value is only used for eventhandler. The worker will use the values from the core for host and service checks. Default: 60 +
job_timeout=60====
max-age:: Threshold for discarding too old jobs. When a new job is older than this amount of seconds it will not be executed and just discarded. This will result in a message like "(Could Not Start Check In Time)". Possible reasons for this are time differences between core and worker (use NTP!) or the smart rescheduler of the core which should be disabled. Set to zero to disable this check. Default: 0 +
max-age=600====
min-worker:: Minimum number of worker processes which should run at any time. Default: 1 +
min-worker=1
max-worker:: Maximum number of worker processes which should run at any time. You may set this equal to min-worker setting to disable dynamic starting of workers. When setting this to 1, all services from this worker will be executed one after another. Default: 20 +
max-worker=20====
spawn-rate:: Defines the rate of spawned worker per second as long as there are jobs waiting. Default: 1 +
spawn-rate=1====
load_limit1:: Set a limit based on the 1min load average. When exceding the load limit, no new worker will be started until the current load is below the limit. No limit will be used when set to 0. Default: no limit +
load_limit1=0====
load_limit5:: Set a limit based on the 5min load average. See 'load_limit1' for details. Default: no limit +
load_limit5=0====
load_limit15:: Set a limit based on the 15min load average. See 'load_limit1' for details. Default: no limit +
load_limit15=0====
idle-timeout:: Time in seconds after which an idling worker exits. This parameter controls how fast your waiting workers will exit if there are no jobs waiting. Set to 0 to disable the idle timeout. Default: 10 +
idle-timeout=30
max-jobs:: Controls the amount of jobs a worker will do before he exits. Use this to control how fast the amount of workers will go down after high load times. Disabled when set to 0. Default: 1000 +
max-jobs=500====
fork_on_exec:: Use this option to disable an extra fork for each plugin execution. Disabling this option will reduce the load on the worker host, but may cause trouble with unclean plugins. Default: no +
fork_on_exec=no====
dupserver:: sets the address of gearman job server where duplicated result will be sent to. Can be specified more than once to add more server. Useful for duplicating results for a reporting installation or remote gui. +
dupserver=logserver:4730,logserver2:4730====
show_error_output:: Use this option to show stderr output of plugins too. When set to no, only stdout will be displayed. Default is yes. +
show_error_output=yes====
timeout_return:: Defines the return code for timed out checks. Accepted return codes are 0 (Ok), 1 (Warning), 2 (Critical) and 3 (Unknown) Default: 2 +
timeout_return=2====
dup_results_are_passive:: Use this option to set if the duplicate result send to the 'dupserver' will be passive or active. Default is yes (passive). +
dup_results_are_passive=yes====
debug-result:: When enabled, the hostname of the executing worker will be put in front of the plugin output. This may help with debugging your plugin results. Default is off. +
debug-result=yes====
enable_embedded_perl:: When embedded perl has been compiled in, you can use this switch to enable or disable the embedded perl interpreter. See <<_embedded_perl,Embedded Perl>> for details on EPN. +
enable_embedded_perl=on====
use_embedded_perl_implicitly:: Default value used when the perl script does not have a "naemon: +epn" or "naemon: -epn" set. Perl scripts not written for epn support usually fail with epn, so its better to set the default to off. +
use_embedded_perl_implicitly=off====
use_perl_cache:: Cache compiled perl scripts. This makes the worker process a little bit bigger but makes execution of perl scripts even faster. When turned off, Mod-Gearman will still use the embedded perl interpreter, but will not cache the compiled script. +
use_perl_cache=on====
restrict_path::
restrict_path allows you to restrict this worker to only execute plugins
from these particular folders. Can be used multiple times to specify more
than one folder.
Note that when this restriction is active, no shell will be spawned and
no shell characters ($&();<>`"'|) are allowed in the command line itself.
+
restrict_path=/usr/local/plugins/====
workaround_rc_25:: Duplicate jobs from gearmand result sometimes in exit code 25 of plugins because they are executed twice and get killed because of using the same ressource. Sending results (when exit code is 25 ) will be skipped with this enabled. Only needed if you experience problems with plugins exiting with exit code 25 randomly. Default is off. +
workaround_rc_25=off====
Queue Names
You may want to watch your gearman server job queue. The shipped gearman_top does this. It polls the gearman server every second and displays the current queue statistics.
+-----------------------+--------+-------+-------+---------+ | Name | Worker | Avail | Queue | Running | +-----------------------+--------+-------+-------+---------+ | check_results | 1 | 1 | 0 | 0 | | host | 3 | 3 | 0 | 0 | | service | 3 | 3 | 0 | 0 | | eventhandler | 3 | 3 | 0 | 0 | | servicegroup_jmx4perl | 3 | 3 | 0 | 0 | | hostgroup_japan | 3 | 3 | 0 | 0 | +-----------------------+--------+-------+-------+---------+
check_results:: this queue is monitored by the neb module to fetch results from the worker. You don't need an extra worker for this queue. The number of result workers can be set to a maximum of 256, but usually one is enough. One worker is capable of processing several thousand results per second.
host:: This is the queue for generic host checks. If you enable host checks with the hosts=yes switch. Before a host goes into this queue, it is checked if any of the local groups matches or a seperate hostgroup machtes. If nothing matches, then this queue is used.
service::
This is the queue for generic service checks. If you enable service
checks with the services=yes switch. Before a service goes into this
queue it is checked against the local host- and service-groups. Then
the normal host- and servicegroups are checked and if none matches,
this queue is used.
hostgroup_--hostgroups=...
to work on hostgroup queues. Note that this queue may also contain
service checks if the hostgroup of a service matches.
servicegroup_servicegroup=... option.
eventhandler::
This is the generic queue for all eventhandler. Make sure you have a
worker for this queue if you have eventhandler enabled. Start the
worker with --events to work on this queue.
perfdata::
This is the generic queue for all performance data. It is created and
used if you switch on --perfdata=yes. Performance data cannot be
processed by the gearman worker itself. You will need
http://www.pnp4nagios.org[PNP4Nagios] therefor.
Performance
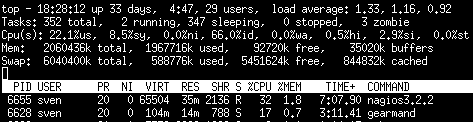
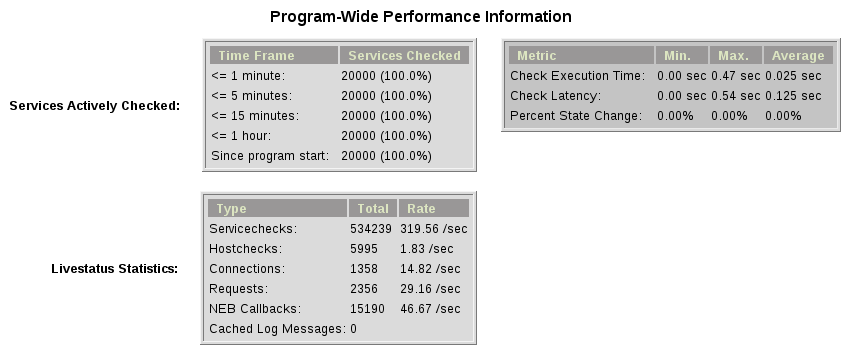
While the main motivation was to ease distributed configuration, this plugin also helps to spread the load on multiple worker. Throughput is mainly limited by the amount of jobs a single Naemon instance can put onto the Gearman job server. Keep the Gearman job server close to the Naemon box. Best practice is to put both on the same machine. Both processes will utilize one core. Some testing with my workstation (Dual Core 2.50GHz) and two worker boxes gave me these results. I used a sample Nagios installation with 20.000 Services at a 1 minute interval and a sample plugin which returns just a single line of output. I got over 300 Servicechecks per second, which means you could easily setup 100.000 services at a 5 minute interval with a single Nagios box. The amount of worker boxes depends on your check types.
++++
 ++++
++++
See this article about benchmarks with https://labs.consol.de/mod-gearman/nagios/omd/2012/10/23/monitoring-core-benchmarks.html[Nagios3, Nagios4 and Mod-Gearman].
Exports
Exports export data structures from the Naemon core as JSON data. For each configurable event one job will be created. At the moment, the only useful event type is the logdata event which allows you to create a json data job for every logged line. This can be very useful for external reporting tools.
exports:: Set the queue name to create the jobs in. The return code will be sent back to the core (Not all callbacks support return codes). Callbacks are a list of callbacks for which you want to export json data. +
export=<queue>:<returncode>:<callback>[,<callback>,...]
export=log_queue:1:NEBCALLBACK_LOG_DATA====
Embedded Perl
Since 1.2.0 Mod-Gearman has builtin embedded Perl support which means generally a big performance boost when you have lots of perl plugins.
To enable embedded Perl you need to run configure with --enable-embedded-perl
./configure --enable-embedded-perl otheroptions...
The --with-perlcache configure option has been replace by a runtime configure option 'use_perl_cache'.
NOTE: Not all perl plugins support EPN. You can fix them, add '# naemon: -epn' in the first 10 lines of the script or set 'use_embedded_perl_implicitly=off' so all scripts without the explicit tag are run without embedded Perl.
The default configuration of Mod-Gearman enables embedded Perl, but only uses it for Perl scripts which explicitly set '# naemon: +epn'. This is a very safe way of using embedded Perl but you probably miss some plugins which do not set the header and still would run with EPN. You may want to use the 'mini_epn' from your Naemon installation to verify if a plugin works with EPN or not.
General EPN documentation is valid for Mod-Gearman as well:
- https://www.naemon.io/documentation/usersguide/embeddedperl.html[Embedded Perl]
- https://www.naemon.io/documentation/usersguide/epnplugins.html[Plugin Guidelines]
NOTE: Mod-Gearman does not fix all of the memory leaks introduced with Naemon and Embedded Perl, but it moves the leaks away from the core. And they do not affect Mod-Gearman at all, as they are only in the preforked worker processes which will be restarted automatically from time to time (see 'max-jobs').
How To
How to Monitor Job Server and Worker
Use the supplied check_gearman to monitor your worker and job server.
Worker have a own queue for status requests.
--------------------------------------
%> ./check_gearman -H <job server hostname> -q worker_<worker hostname> -t 10 -s check
check_gearman OK - localhost has 10 worker and is working on 1 jobs|worker=10 running=1 total_jobs_done=1508
--------------------------------------
This will send a test job to the given job server and the worker will
respond with some statistical data.
Job server can be monitored with:
--------------------------------------
%> ./check_gearman -H localhost -t 20
check_gearman OK - 6 jobs running and 0 jobs waiting.|check_results=0;0;1;10;100 host=0;0;9;10;100 service=0;6;9;10;100
--------------------------------------
How to Submit Passive ChecksYou can use send_gearman to submit active and passive checks to a gearman job server where they will be processed just like a finished check would do.
%> ./send_gearman --server= --encryption=no --host="" --service="" --message="message"
How to build send_gearman.exe
After installing strawberry perl, you need to install the
'PAR::Packer' module and run pp:
--------------------------------------
pp -l zlib1__.dll -l ssleay32__.dll -l libeay32__.dll -x -z 9 -o send_gearman.exe send_gearman.pl
--------------------------------------
Or just use the prebuild one from labs.consol.de:
http://mod-gearman.org/archive/send_gearman.zip[send_gearman.exe].
How to Submit check_multi Resultscheck_multi is a plugin which executes multiple child checks. See more details about the feed_passive mode at: http://www.my-plugin.de/wiki/projects/check_multi/feed_passive[www.my-plugin.de]
You can pass such child checks to Naemon via the mod_gearman neb module:
%> check_multi -f multi.cmd -r 256 | ./send_multi --server= --encryption=no --host="" --service=""
If you want to use only check_multi and no other workers, you can achieve this with the following neb module settings:
broker_module=/usr/local/share/naemon/mod_gearman_naemon.o server=localhost encryption=no eventhandler=no hosts=no services=no hostgroups=does_not_exist config=.../module.conf
NOTE: encryption is not necessary if you both run the check_multi checks and the Naemon check_results queue on the same server.
How to Set Queue by Custom Variable
Set 'queue_custom_variable=worker' in your Mod-Gearman NEB
configuration. Then adjust your Naemon host/service configuration and
add the custom variable:
-------
define host {
...
_WORKER hostgroup_test
}
-------
The test hostgroup does not have to exist, it is a virtual queue name
which is used by the worker.
Adjust your Mod-Gearman worker configuration and put 'test' in the
'hostgroups' attribute. From then on, the worker will work on all jobs
in the 'hostgroup_test' queue.
Notifications
-------------
Starting with version 3.0.2 Mod-Gearman does distribute Notifications as well.
All Notifications (except bypassed by local groups) are send into the notifications
queue and processed from there.
Mod-Gearman does not support environment macros, except two plugin output related
ones.
It does set
- NAGIOS_SERVICEOUTPUT
- NAGIOS_LONGSERVICEOUTPUT
for service notifications and
- NAGIOS_HOSTOUTPUT
- NAGIOS_LONGHOSTOUTPUT
for host notifications.
Supported Dependencies
----------------------
NOTE: Mod-Gearman works best with libgearman/gearmand 0.33 and Naemon. If in
doubt, use these versions.
Lib-GearmanMod-Gearman has successfully been tested on the following Gearmand Versions. It is recommended to always use the latest listed version of libgearman.
- https://github.com/gearman/gearmand/releases/tag/1.1.19.1[libgearman 1.1.19.1]
- https://launchpad.net/gearmand/trunk/0.33[libgearman 0.33]
- https://launchpad.net/gearmand/trunk/0.32[libgearman 0.32]
- https://launchpad.net/gearmand/trunk/0.25[libgearman 0.25]
- https://launchpad.net/gearmand/trunk/0.23[libgearman 0.23]
- https://launchpad.net/gearmand/trunk/0.14[libgearman 0.14]
Naemon
Mod-Gearman works perfectly with all versions of the Naemon core.
* http://naemon.io[Naemon]
NagiosMod-Gearman dropped support for Nagios 3 starting with Mod-Gearman 4.x. Use a 3.x release from the archive if you still need that.
Icinga
Mod-Gearman dropped support for Icinga 1 starting with Mod-Gearman
4.x. Use a 3.x release from the archive if you still need that.
Hints
-----
- Make sure you have at least one worker for every queue. You should
monitor that (check_gearman).
- Add Logfile checks for your gearmand server and mod_gearman
worker.
- Make sure all gearman checks are in local groups. Gearman self
checks should not be monitored through gearman.
- Checks which write directly to the Naemon command file (ex.:
check_mk) have to run on a local worker or have to be excluded by
the localservicegroups.
- Keep the gearmand server close to Naemon for better performance.
- If you have some checks which should not run parallel, just setup a
single worker with --max-worker=1 and they will be executed one
after another. For example for cpu intesive checks with selenium.
- Make sure all your worker have the Monitoring-Plugins available under
the same path. Otherwise they could'nt be found by the worker.