



⚙ A Web Scraper built with selenium, that fetches all the course info you will ever need.
Usage | Installation | Contributors | License
### **NOTE** I won't be actively working on this project anymore as udemy has setup some sort of scraping protection. But feel free to fork and extend it. It was fun making this project and I learnt a lot of stuff, but ig it's time to move on now ... Will be archiving this on May 5th 2022. > ## 📌 New in 0.8.x/2 Series > > ### Added > > - #### **Udemyscraper** can now export multiple courses to csv files! > - `course_to_csv` takes an array as an input and dumps each course to a single csv file. > - #### **Udemyscraper** can now export courses to xml files! > - `course_to_xml` is function that can be used to export the course object to an xml file with the appropriate tags and format. > - `udemyscraper.export` submodule for exporting scraped course. > - Support for Microsoft Edge (Chromium Based) browser. > - Support for Brave Browser. > - Support for Vivaldi. > - Tests for module, exporting and scripts. > - Added bulk export of courses with script. > > ### Changes > > - #### **Udemyscraper.py** has been refractured into 5 different files: > - `__init__.py` - Contains the code which will run when imported as a library > - `metadata.py` - Contains metadata of the package such as the name, version, author, etc. Used by setup.py > - `output.py` - Contains functions for outputting the course information. > - `udscraperscript.py` -Is the script file which will run when you want to use udemyscraper as a script. > - `utils.py` - Contains utility related functions for udemyscraper. > - #### Renamed repository to udemyscraper. > - #### Now using udemyscraper.export instead of udemyscraper.output. > > - `quick_display` function has been replaced with `print_course` function. > > - #### Now using `setup.py` instead of `setup.cfg` > - #### Deleted `src` folder which is now replaced by `udemyscraper` folder which is the source directory for all the modules > - ### **Installation Process** > > #### Since udemyscraper is now to be used as a package, it is obvious that the installation process has also had major changes. > > Installation process is documented [here](readme.md/#Installation) > > - Renamed the `browser_preference` key in Preferences dictionary to `browser` > - Relocated browser determination to `utils` as `set_browser` function. > - Removed `requirements.txt` and `pyproject.toml` > > ### Fixed > > - Fixed cache argument bug. > - Fixed importing preferences bug. > - Fixed Banner Image scraping. > - Fixed Progressbar exception handling. > - Fixed recognition of chrome as a valid browser. > - Preferences will not be printed while using the script. > - Fixed `browser` key error > - Exporting to xml always defaults to course.xml filename. > - 'TypeError': 'module' object is not callable Check out [CHANGELOG](CHANGELOG.md) for more changes and version updates. # Usage This section shows the basic usage of this script. Before this be sure to [install](#installation) this first before importing it in your file. ## As a Module Udemyscraper contains a `UdemyCourse` class which can be imported into your file it takes just one argument which is `query` which is the seach query. It has a method called `fetch_course` which you can call after creating a UdemyCourse object. ```py from udemyscraper import UdemyCourse course = UdemyCourse() course.fetch_course('learn javascript') print(course.title) # Prints courses' title ``` ## As a Script In case you do not wish to use the module in your own python file but you just need to dump the data, udemyscraper can be directly invoked along with a variety of arguments and options. You can do so by running the udemyscraper. There is no need to worry about your `PATH` as it is automatically configured by pip on installation. ```bash udemyscraper --no-warn --query "Learn Python for beginners" ``` Here is an example of exporting the data as a json file. ```bash udemyscraper -d json -q "German course for beginners" ``` You can also use a `.txt` file containing 1 query per line. ```bash udemyscraper -q "queries.txt" ``` Udemyscraper can export the data to a variety of formats as shown [here](#output-dumping-data) ### List of Commands  # Installation For installing the latest stable version of `Udmyscraper` you can simply install it using pip. ```PowerShell pip install udemyscraper ``` Or if you like to live on the edge then you can always use the current build in the repo (**Not Recommmended**)- - Clone it- ```PowerShell git clone https://github.com/sortedcord/udemyscraper.git && cd udemyscraper ``` - Install it- ```PowerShell pip install -e .[dev] ``` - Use it- ```py udemyscraper --version ``` ## Dependencies Installation Dependcies will be automatically installed with pip. If you do want to look at all the dependencies of this project you can always check out [setup.py](setup.py) or [Dependecy Graph](https://github.com/sortedcord/udemyscraper/network/dependencies). > ### Deprecated as of 0.8.0 > > Earlier there used to be a `requirements.txt` file which you would use to install the dependencies. # Browser Setup A browser window may not pop-up as I have enabled the `headless` option so the entire process takes minimal resources. This script works with firefox as well as chromium based browsers. Make sure the webdrivers of Chrome, Edge and Firefox are added to your path while using the respected browsers. ## Chrome (or chromium) To run this script you need to have chrom(ium) installed on the machine as well as the chromedriver binary which can be downloaded from this [page](https://chromedriver.chromium.org/downloads). Make sure that the binary you have installed works on your platform/ architecture and the the driver version corresponds to the version of the browser you have downloaded. To set chrome as default you can pass in an argument while initializing the class though it is set to chrome by default. ```py mycourse = UdemyCourse(browser="chrome") ``` Or you can pass in a argument while using as a script ```bash udemyscraper -b chrome ``` ## Edge To run this script you need to have Microsoft Edge installed on the machine as well as the msedgedriver which can be downloaded from this [page](https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/). Make sure that the binary you have installed works on your platform/ architecture and the the driver version corresponds to the version of the browser you have downloaded. In order to use edge, you can pass in an argument while initializing the class. ```py mycourse = UdemyCourse(browser="edge") ``` Or you can pass in a argument while using as a script ```bash udemyscraper -b edge ``` ### Using other chromium browsers With update 0.8.0 you can now use other chromium browsers such as brave and vivaldi along with udemyscraper. The process is similiar to using the other browsers, just that you need to have chromedriver added to the path. Brave works with windows as well as with linux however udemyscraper has not been tested with macOS yet. ```py mycourse = UdemyCourse(browser="brave") ``` ## Firefox In order to run this script this firefox, you need to have firefox installed as well as the `gekodriver` executable file in this directory or in your path. You can download the gekodriver from [here](https://github.com/mozilla/geckodriver/releases). Or use the one provided with the source code. To use firefox instead of chrome, you can pass in an argument while initializing the class: ```py mycourse = UdemyCourse(browser="firefox") ``` Or you can pass in a argument while using `udemyscraper.py` ```bash udemyscraper -b firefox ``` ## Suppressing Browser | **Headless Disabled** | **Headless Enabled** | | ------------------------------------- | -------------------------------------- | | 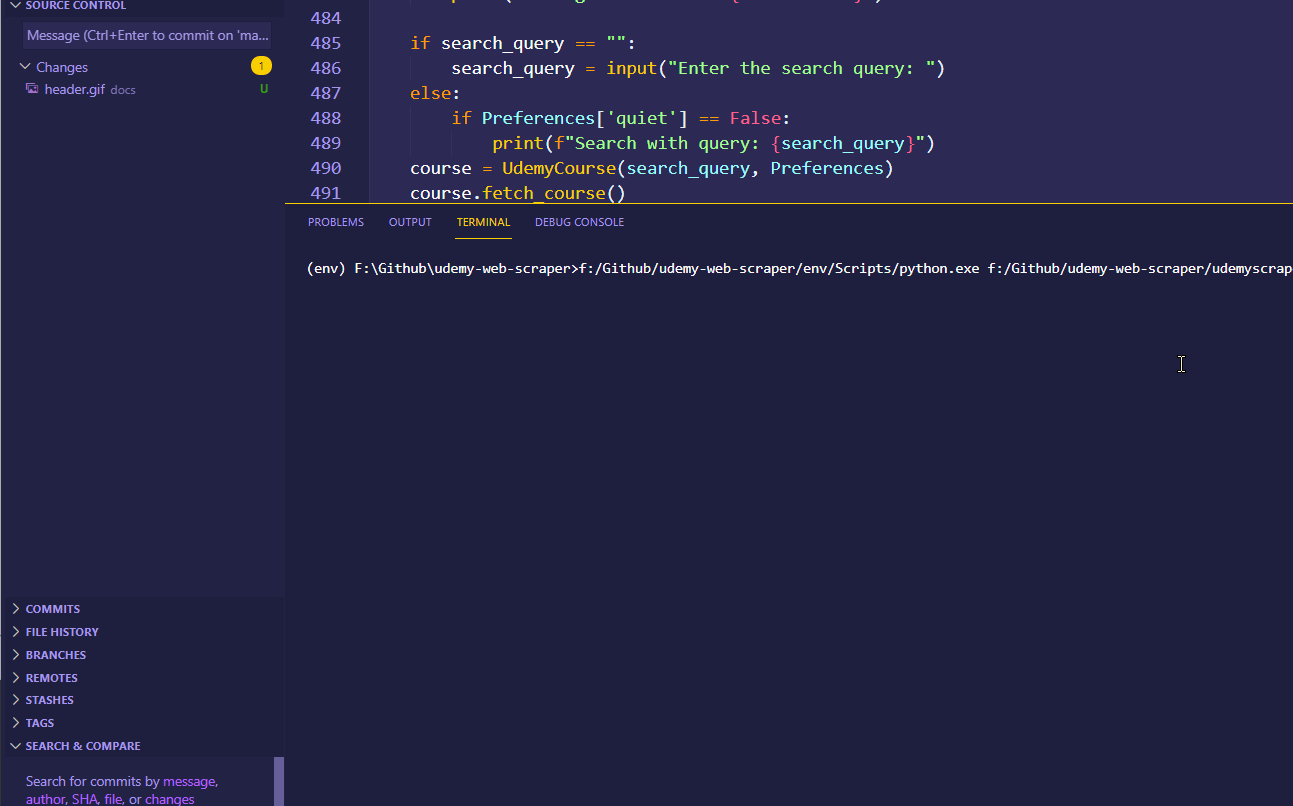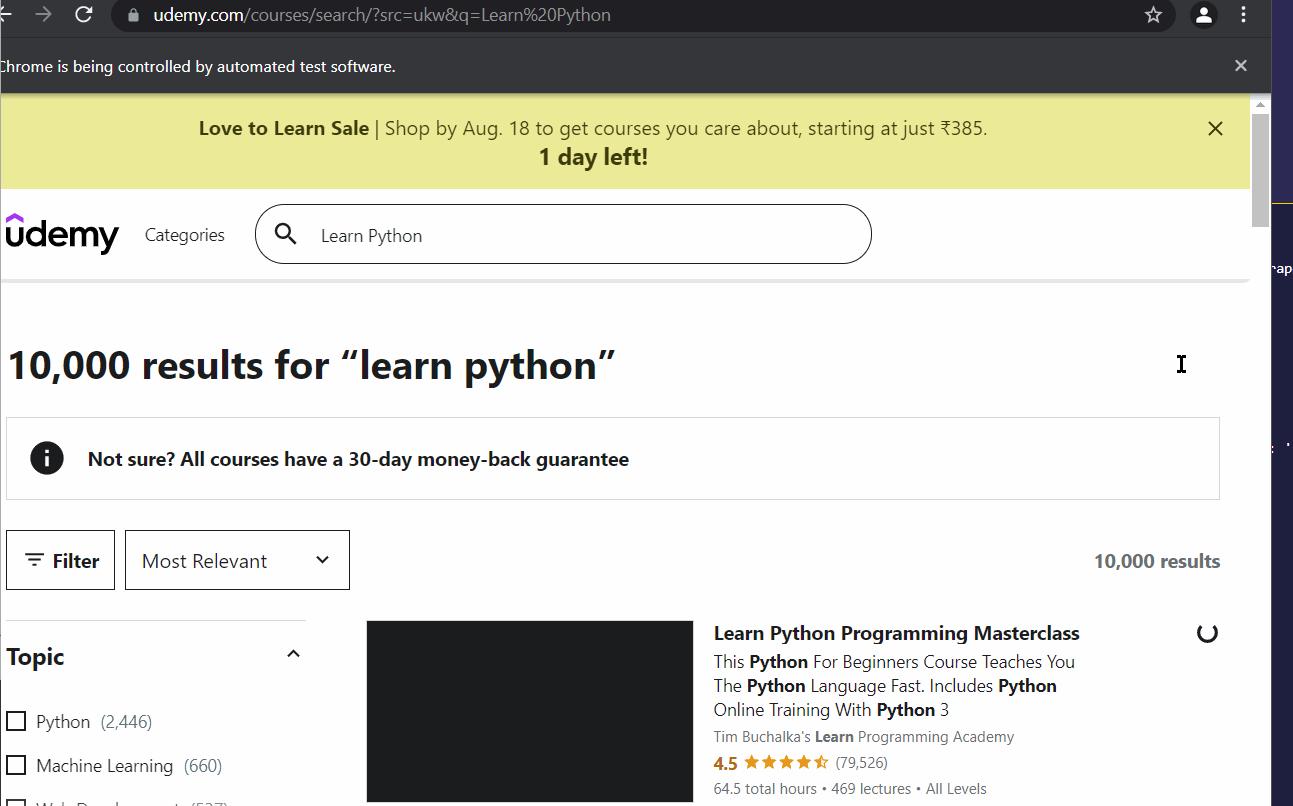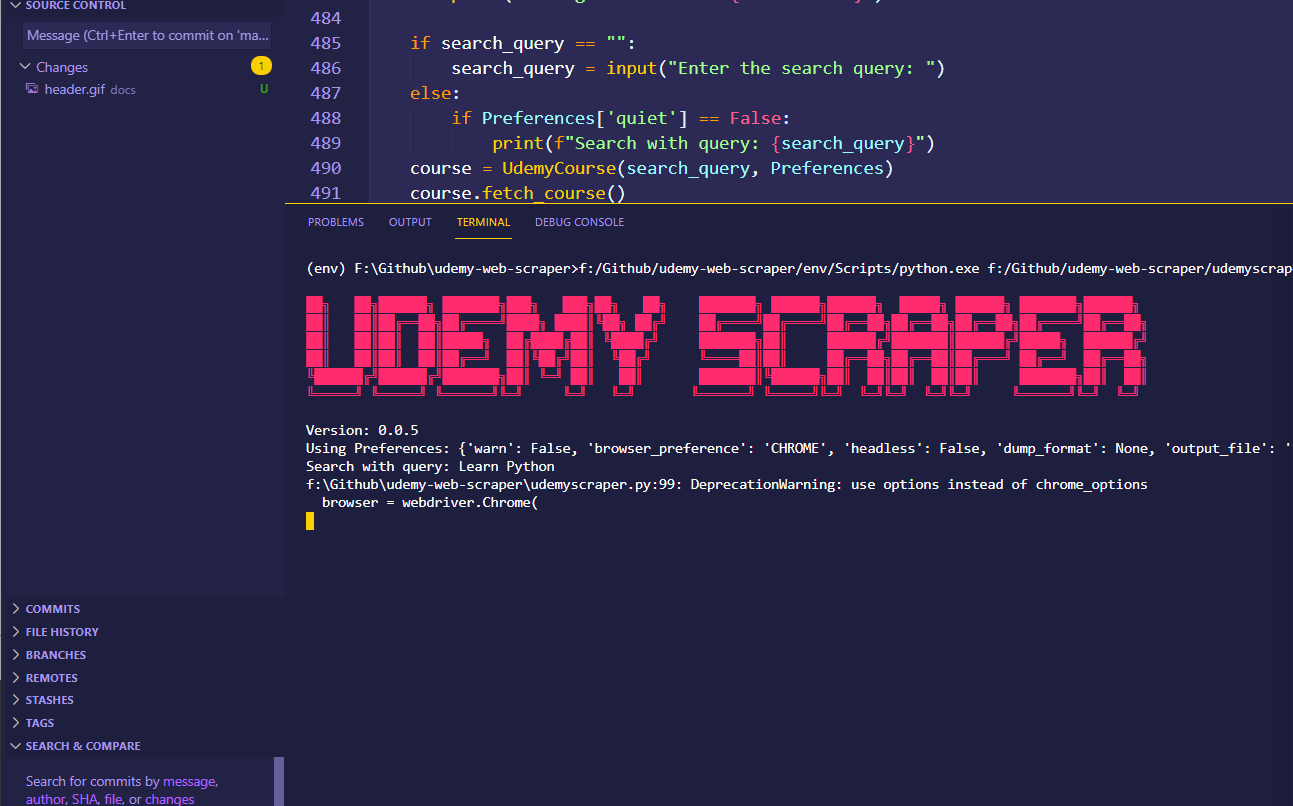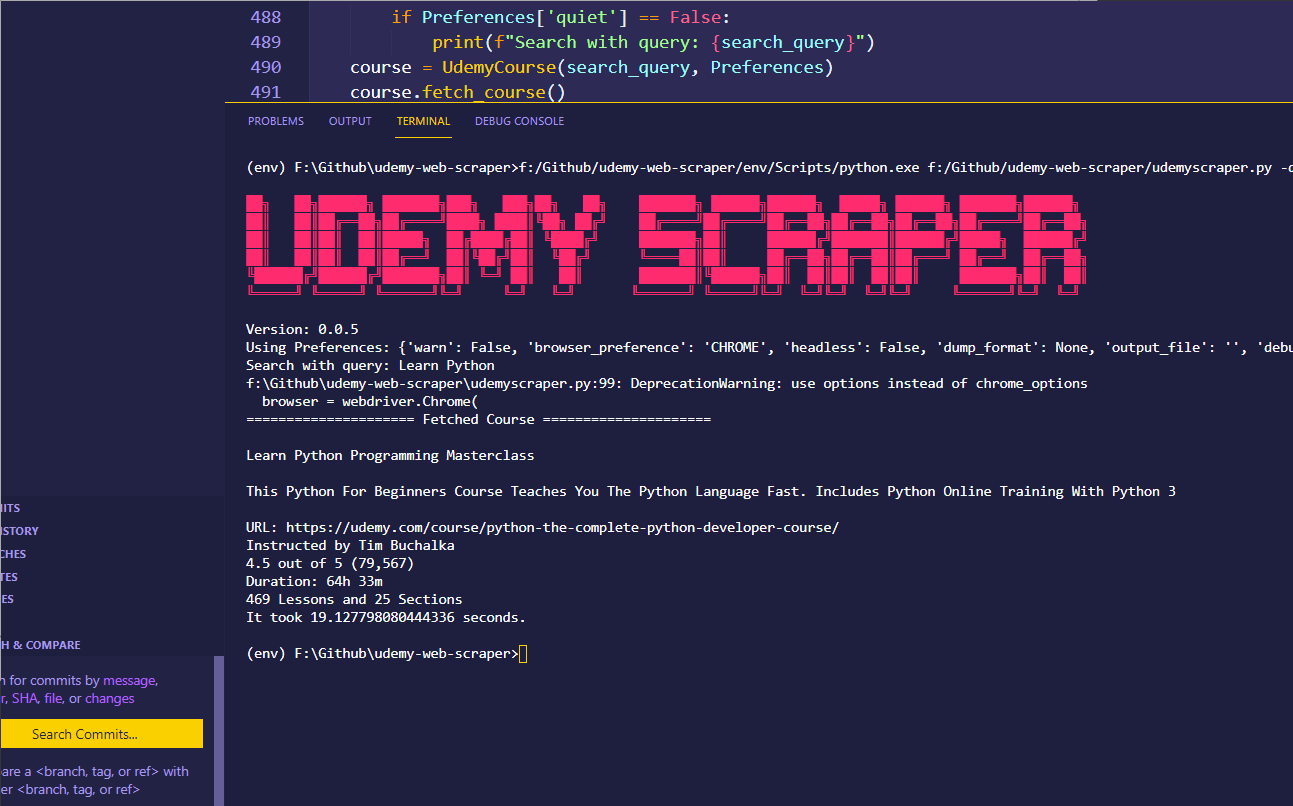 |  | | 19 Seconds | 12 Seconds | In the above comparison you can clearly see that the image on the right (headless) completed way faster than the one with headless disabled. By suppressing the browser not only do you save time, but you also save system resources. The `headless` option is enabled by default. But in case you want to disable it for debugging purposes, you may do so by passing the `headless` argument to `false` ```py mycourse = UdemyCourse(headless=False) ``` Or specify the same for `udemyscraper.py` ```bash udemyscraper -h false ``` # Data The following datatable contains all of the data that can be fetched. ## Course Class This is the data of the parent class which is the course class itself.
View Table
| Name | Type | Description | Usage | | ----------------- | ------------ | -------------------------------------------------------- | ------------------------ | | `link` | URL (String) | url of the course. | `course.link` | | `title` | String | Title of the course | `course.title` | | `headline` | String | The headline usually displayed under the title | `course.headline` | | `instructors` | String | Name of the instructor of the course | `course.instructors` | | `rating` | Float | Rating of the course out of 5 | `course.rating` | | `no_of_ratings` | Integer | Number of rating the course has got | `course.no_of_ratings` | | `duration` | String | Duration of the course in hours and minutes | `course.duration` | | `no_of_lectures` | Integer | Gives the number of lectures in the course (lessons) | `course.no_of_lectures` | | `no_of_sections` | Integer | Gives the number of sections in the courses | `course.no_of_lectures` | | `tags` | List | Is the list of tags of the course (Breadcrumbs) | `course.tags[1]` | | `price` | Float | Price of the course in local currency | `course.price` | | `student_enrolls` | Integer | Gives the number of students enrolled | `course.student_enrolls` | | `language` | String | Gives the language of the course | `course.language` | | `objectives` | List | List containing all the objectives for the course | `course.objectives[2]` | | `Sections` | List | List containing all the section objects for the course | `course.Sections[2]` | | `requirements` | List | List containing all the requirements for the course | `course.requirements` | | `description` | String | Gives the description paragraphs of the course | `course.description` | | `target_audience` | List | List containing the points under Target Audience heading | `course.target_audience` | | `banner` | String | URL for the course banner image | `course.banner` |
```bash
$ udemyscraper -q "Learn Python" --quiet -n --dump print
===================== Fetched Course =====================
Learn Python Programming Masterclass
This Python For Beginners Course Teaches You The Python
Language Fast. Includes Python Online Training With Python 3
URL: https://udemy.com/course/python-the-complete-python-developer-course/
Instructed by Tim Buchalka
4.5 out of 5 (79,526)
Duration: 64h 33m
469 Lessons and 25 Sections
```
The `print_course` function can also be called when using udemyscraper as a module.
```py
from udemyscraper.export import export_course
# Assuming you have already created a course object and fetched the data
export_course(course, "print")
```
## Converting to Dictionary
The entire course object is converted into a dictionary by using nested object to dictionary conversion iterations.
```py
from udemyscraper.export import export_course as exp
# Assuming you have already created a course object and fetched the data
dictionary_course = exp(course, "dict")
```
## Dumping as JSON
Udemyscraper can also convert the entire course into a dictionary, parse it into a json file and then export it to a json file.
```py
from udemyscraper.export import export_course
# Assuming you have already created a course object and fetched the data
export_course(course, "json", "custom_name.json")
```
This will export the data to `object.json` file in the same directory. You can also specify the name of the file by passing in the corresponding argument
Here is an example of how the file will look like. (The file has been trunacted)

## Dumping as CSV
With update 0.8.0 you can export the scraped data to a CSV file. This is more useful when dealing with multiple course classes.
When exporting the course to a csv file, be sure to convert it to an array and then use the `export_course` function on it.
```py
from udemyscraper import UdemyCourse
from udemyscraper.export import export_course
course = UdemyCourse({'cache': True, 'warn':False})
course.fetch_course("learn javascript")
course2 = UdemyCourse({'warn':False, 'debug': True})
course2.fetch_course("learn german")
export_course([course, course2], "csv")
```
This code will export something like this-
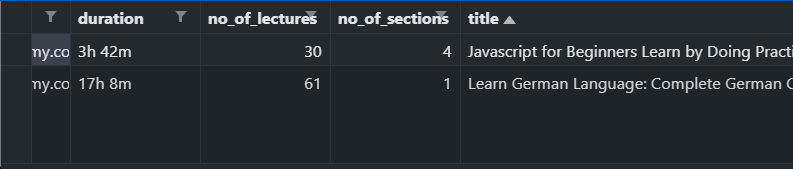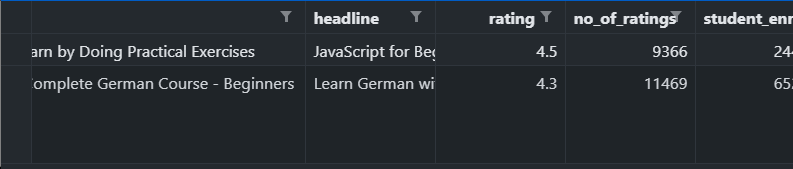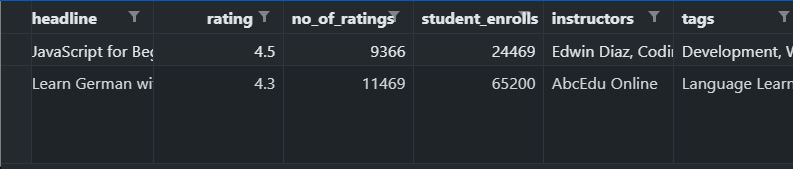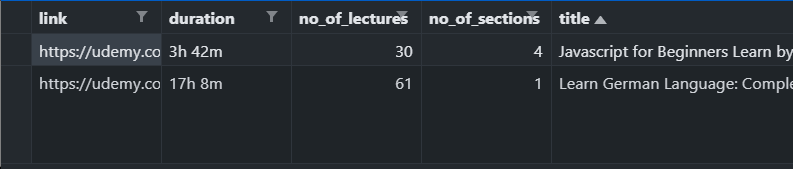
You can do this with as many number of courses you like. But unfortunately, I couldn't figure out any way to export sections and lessons to csv.
## Dumping as XML
Udemyscraper can also convert the entire course into a dictionary, parse it into xml and then export it to an xml file.
```py
from udemyscraper.export import export_course
# Assuming you have already created a course object and fetched the data
export_course(course, "xml", "custom_name.xml")
```
This will export the data to `object.json` file in the same directory. You can also specify the name of the file by passing in the corresponding argument
Here is an example of how the file will look like. (The file has been trunacted)

### For Jellyfin users
Jellyfin metadata uses XML structure for its `.nfo` files. For images, we only have one resource which is the poster of the file. It might be possible to write a custom XML structure for jellyfin. Currently in development.
# Approach
It is fairly easy to webscrape sites, however, there are some sites that are not that scrape-friendly. Scraping sites, in itself is perfectly legal however there have been cases of lawsuits against web scraping, some companies \*cough Amazon \*cough consider web-scraping from its website illegal however, they themselves, web-scrape from other websites. And then there are some sites like udemy, that try to prevent people from scraping their site.
Using BS4 in itself, doesn't give the required results back, so I had to use a browser engine by using selenium to fetch the courses information. Initially, even that didn't work out, but then I realised the courses were being fetch asynchronously so I had to add a bit of delay. So fetching the data can be a bit slow initially.
## Why not just use Udemy's API?
Idk, u tell me, would it still be called a web scraper then?
# Contributing
Issues and PRs as well as discussions are always welcomes, but please make an issue of a feature/code that you would be modifying before starting a PR.
Currently there are lots of features I would like to add to this script. You can check [this page](https://github.com/sortedcord/udemyscraper/projects/1) what the current progress is.
For further instructions, do read [contributing.md](CONTRIBUTING.md).
Thanks to these contributors who made the project maintained!
|  |  |
| :--------------------------------------: | :--------------------------------------: |
| [Sortedcord](https://www.github.com/sortedcord) | [flyingcakes85](https://www.github.com/flyingcakes85)