Introduction to TensorFX
TensorFX is an end to end application framework to simplifies machine learning with TensorFlow - both training models and using them for prediction. It is designed from the ground up to make the mainline scenarios simple with higher level building blocks, while ensuring custom or complex scenarios remain possible by preserving the flexibility of TensorFlow APIs.
There are some important principles that shape the design of the framework:
-
Simple, consistent set of usage patterns Local or cloud, single node or distributed execution, in-memory data or big data sharded across files, you should have to write code once, in a single way regardless of how the code executes.
-
A Toolbox with Useful Abstractions The right entrypoint for the task at hand, starting with off-the-shelf algorithms that let you focus on feature engineering and hyperparam tuning. If you need to solve something unqiue, you can focus on building TensorFlow graphs, rather than infrastructure code (distributed cluster setup, checkpointing, logging, exporting models etc.).
-
Declarative Using YAML, JSON, and simplified Python interfaces to minimize the amount of boilerplate code.
OK, enough context... here is some information to get you started.
Getting Started
Once you have a Python environment (recommendation: use Miniconda), installation is straightforward:
pip install tensorflow
pip install tensorfxNote that TensorFX depends on TensorFlow 1.0, and supporting libraries such as numpy and pandas.
Documentation
Documentation is at https://tensorlab.github.io/tensorfx/. This includes API reference topics, as well as conceptual and how-to topics. They are a work-in-progress, but check them out! There are a few samples that demonstrate how to get started as well in the repository. Likewise, more to be added over time.
Contributions and Development
We welcome contributions in form of ideas, issues, samples as well as code. Since the project is at a super-early stage, and evolving rapidly, its best to start a discussion by filing an issue for any contribution.
Building and Testing
If you want to develop within the repository, clone it, and run the following commands:
# Install requirements and setup envionment
source init.sh install
# Build and Test
./build.sh testRelated Links
- Development workflow [TODO: Add wiki entry]
Hello World - Iris Classification Model
This sample here is a quick 5-minute introduction to using TensorFX. Here is the code for building a feed-forward neural network classification model for the iris dataset.
import tensorfx as tfx
import tensorfx.models.nn as nn
# Hyperparameters, training parameters, and data
args, job = nn.FeedForwardClassificationArguments.parse(parse_job=True)
dataset = tfx.data.CsvDataSet(args.data_schema,
train=args.data_train,
eval=args.data_eval,
metadata=args.data_metadata,
features=args.data_features)
# Instantiating the model builder
classification = nn.FeedForwardClassification(args, dataset)
# Training
trainer = tfx.training.ModelTrainer()
model = trainer.train(classification, job)
# Prediction
instances = [
'6.3,3.3,6,2.5', # virginica
'4.4,3,1.3,0.2', # setosa
'6.1,2.8,4.7,1.2' # versicolor
]
predictions = model.predict(instances)Here's an outline steps to perform for basic usage of what TensorFX offers:
- Parse (or build) an Arguments object, usually from the command-line to define hyperparameters.
This object corresponds to the kind of model you are training, so,
FeedForwardClassificationArgumentsin this case. - Create a DataSet to reference training and evaluation data, along with supporting configuration - namely - schema, metadata, and features (more on these below).
- Initialize the model builder - in this case
FeedForwardClassification. - Initialize the model trainer, and invoke
train()which runs the training process to return a model. - Load some instances you want to run through the model and call
predict().
Schema - schema.yaml
The schema describes the structure of your data. This can be defined programmatically, but is conveniently expressible in declarative YAML form, and placed alongside training data.
fields:
- name: species
type: discrete
- name: petal_length
type: numeric
- name: petal_width
type: numeric
- name: sepal_length
type: numeric
- name: sepal_width
type: numericMetadata - metadata.json
Metadata is the result of analyzing training data, based on type information in the schema. Iris is a tiny dataset, so metadata is readily producable using simple python code looping over the data. For real-world and large datasets, you'll find Spark and BigQuery (on Google Cloud Platform) as essential data processing runtimes. Stay tuned - TensorFX will provide support for these capabilities out of the box.
{
"species": { "entries": ["setosa", "virginica", "versicolor"] },
"petal_length": { "min": 4.3, "max": 7.9 },
"petal_width": { "min": 2.0, "max": 4.4 },
"sepal_length": { "min": 1.1, "max": 6.9 },
"sepal_width": { "min": 0.1, "max": 2.5 }
}Features - features.yaml
Like schema, features can also be defined programmatically, or expressed in YAML. Features describe the set of inputs that your models operate over, and how they are produced by applying transformations to the fields in your data. These transformations are turned into TensorFlow graph constructs and applied consistently to both training and prediction data.
In this particular example, the FeedForwardClassification model requires two features: X defining the values the model uses for producing inferences, and Y, the target label that the model is expected to predict which are defined as follows:
features:
- name: X
type: concat
features:
- name: petal_width
type: scale
- name: petal_length
type: scale
- name: sepal_width
type: log
- name: sepal_length
type: log
- name: Y
type: target
fields: speciesRunning the Model
The python code in the sample can be run directly, or using a train tool, as shown:
cd samples
tfx train \
--module iris.trainer.main \
--output /tmp/tensorfx/iris/csv \
--data-train iris/data/train.csv \
--data-eval iris/data/eval.csv \
--data-schema iris/data/schema.yaml \
--data-metadata iris/data/metadata.json \
--data-features iris/features.yaml \
--log-level-tensorflow ERROR \
--log-level INFO \
--batch-size 5 \
--max-steps 2000 \
--checkpoint-interval-secs 1 \
--hidden-layers:1 20 \
--hidden-layers:2 10Once the training is complete, you can list the contents of the output directory. You should
see the model (the prediction graph, and learnt variables) in the model subdirectory, alongside
checkpoints, and summaries.
ls -R /tmp/tensorfx/iris/csv
checkpoints job.yaml model summaries
/tmp/tensorfx/iris/csv/checkpoints:
checkpoint model.ckpt-2000.index
model.ckpt-1.data-00000-of-00001 model.ckpt-2000.meta
model.ckpt-1.index model.ckpt-2001.data-00000-of-00001
model.ckpt-1.meta model.ckpt-2001.index
model.ckpt-1562.data-00000-of-00001 model.ckpt-2001.meta
model.ckpt-1562.index model.ckpt-778.data-00000-of-00001
model.ckpt-1562.meta model.ckpt-778.index
model.ckpt-2000.data-00000-of-00001 model.ckpt-778.meta
/tmp/tensorfx/iris/csv/model:
saved_model.pb variables
/tmp/tensorfx/iris/csv/model/variables:
variables.data-00000-of-00001 variables.index
/tmp/tensorfx/iris/csv/summaries:
eval prediction train
/tmp/tensorfx/iris/csv/summaries/eval:
events.out.tfevents.1488351760
events.out.tfevents.1488352853
/tmp/tensorfx/iris/csv/summaries/prediction:
events.out.tfevents.1488351765
/tmp/tensorfx/iris/csv/summaries/train:
events.out.tfevents.1488351760
events.out.tfevents.1488352852Summaries are TensorFlow events logged during training. They can be observed while the training job is running (which is essential when running a long or real training job) to understand how your training is progressing, or how the model is converging (or not!).
tensorboard --logdir /tmp/tensorfx/iris/csvThis should bring up TensorBoard. Its useful to see the graph structure, metrics and other tensors that are automatically published.
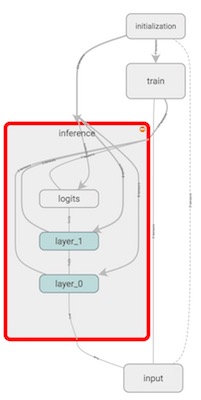
Training Graph
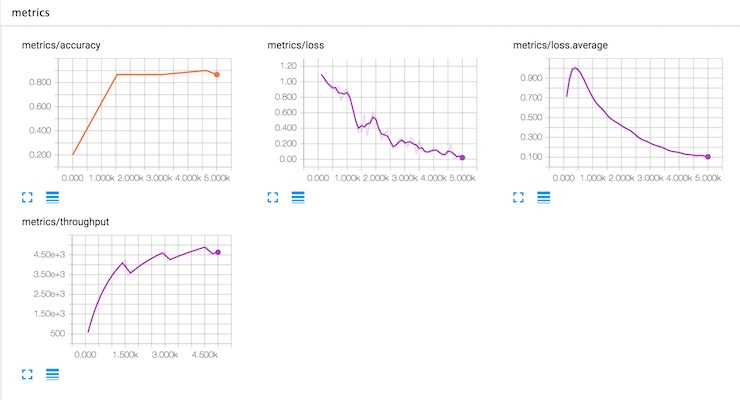
Training Metrics -- Accuracy, Loss and Throughput
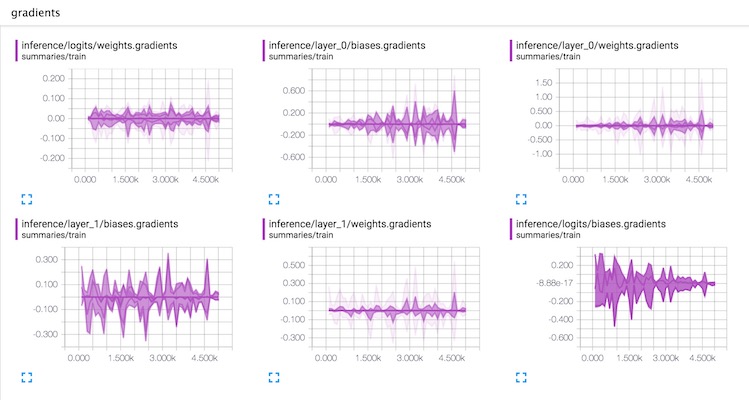
Model Variables -- Weights, Gradients, etc.
As you can see, the out-of-box model takes care of a number of details. The same code can be run on a single machine, or in a cluster (of course, iris is too simple of a problem to need that).