beancount-parser-lima
A zero-copy parser for Beancount in Rust.
It is intended to be a complete implementation of the Beancount file format, except for those parts which are deprecated and other features as documented here (in a list which may not be comprehensive).
Currently under active development. APIs are subject to change, but I hope not majorly.
The slightly strange name is because of a somewhat careless failure on my part to notice the existing beancount-parser when starting this project, for which apologies.
Features
-
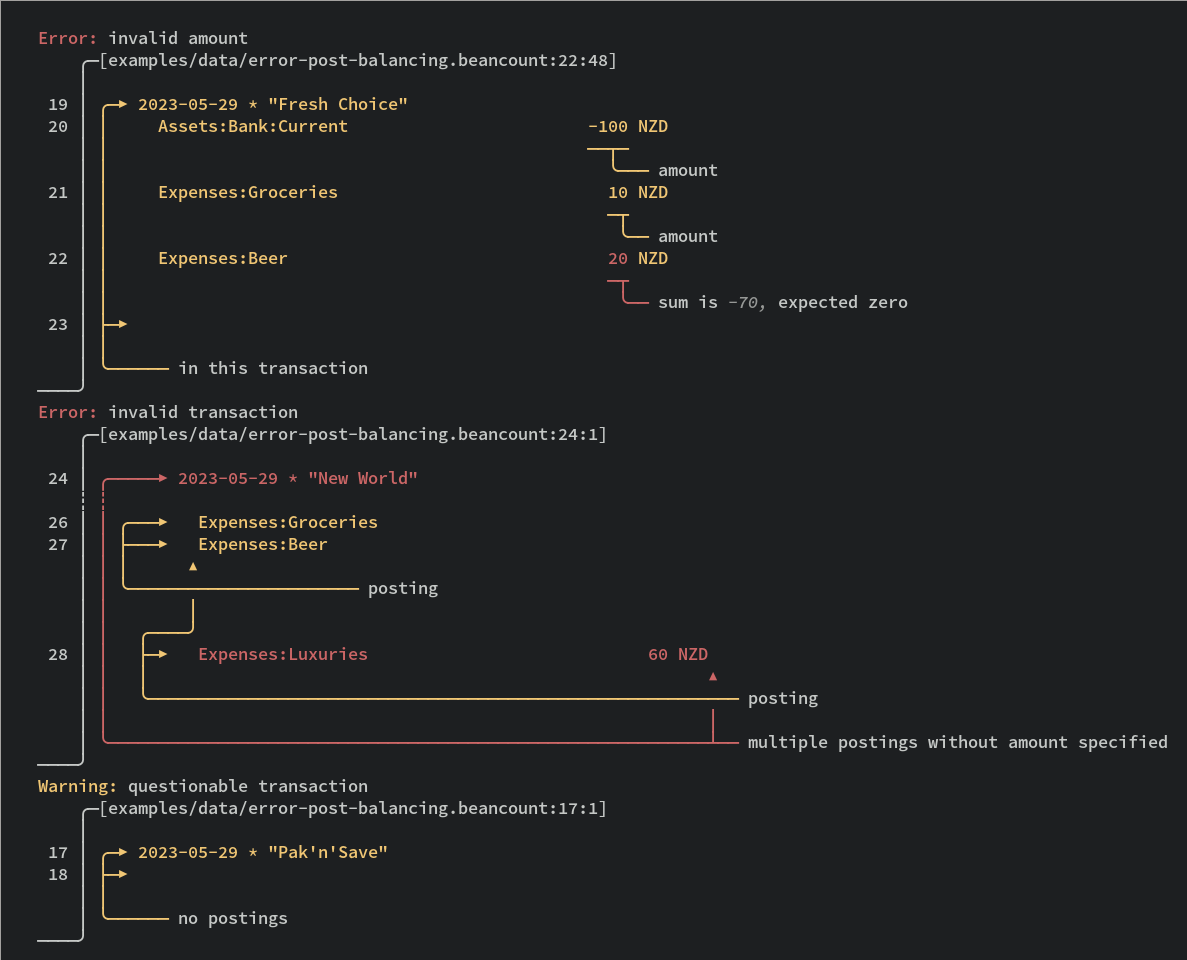
beautiful error messages, thanks to Ariadne
-
interface for applications to also report beautiful errors in their original context, as in the example below
-
focus on conceptual clarity of application domain objects mapped to Rust types
-
Python bindings (work-in-progress)
Roadmap and Status
-
create Python bindings, so that this could be a drop-in replacement for the existing Beancount parser (which is not to say it will necessarily become that!)
-
improve API in the light of experience, i.e. when it gets some use 😅
-
address mistakes, misunderstandings, and edge-cases in the initial implementation as they are discovered
beancount-parser-lima v0.2.1 is able to parse the example.beancount file from the official Beancount repo.
Examples
dump
This simply parses a Beancount file and outputs the results of parsing, using the Display implementations for the parser output types.
The special filename STDIN causes it to read instead from standard input and parse the resulting inline string.
cargo run --example dump -- ./examples/data/full.beancountcheck
This is an example of reporting errors against source locations by the application rather than the parser. This is important as semantic errors are not the business of the core parser to detect and report.
cargo run --example check -- ./examples/data/full.beancountUncertainties / TODOs
Yeah, Beancount is complicated, and I may have made some mistakes here. Current list of uncertainties, which is certainly not comprehensive.
- metadata tags/links for a directive get folded in with those in the directive header line
Unsupported
This is an incomplete list of what is currently unsupported.
- custom directive
Unsupported Options
allow_pipe_separatorallow_deprecated_none_for_tags_and_linksdefault_toleranceexperiment_explicit_tolerancesinsert_pythonpathplugintoleranceuse_legacy_fixed_tolerances
Also, unary options are not supported.
Parser Tests
The parser test cases are based on the parser tests from Beancount itself, extracted into a language independent format. That is, all the original tests have been replicated here, with some additions.
Each test comprises a Beancount file and expected parse output formatted as Protobuf Text Format Language, using the Beancount Protobuf schema from the Beancount repo.
Error cases in this repo have been converted to match the expected error message output of this parser.
Behaviour which differs from original Beancount parser has been annotated in the test with ANOMALY.
Tests for features unsupported in the Lima parser are left in test-cases-unsupported.
Alpha Status Dependencies
-
Chumsky
1.0.0.alpha.*releases are required for zero-copy support -
smallvec
2.0.0-alpha.*releases are required for correct lifetime inference
Alternatives
beancount-parser is another parser for Beancount which predates this one, using nom instead of Chumsky.
License
Licensed under either of
- Apache License, Version 2.0 LICENSE-APACHE
- MIT license LICENSE-MIT
at your option.
Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in the work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.