ZooKeeper C++
A ZooKeeper client for C++. It is hosted on GitHub, documented (including previous versions of the software), and tested.
Features include (but are not necessarily limited to):
-
Simple
- Connect with just a connection string
- Clients should not require factories
- Does not require knowledge of the Java or C APIs
-
Configurable
- Use the parts you need
- Change parts to fit in your application
-
Safe
- In the best case, illegal code should fail to compile
- An illegal action should throw an exception
- Utility functions have a strong exception guarantee
-
Stable
- Worry less about upgrading -- the API and ABI will not change out from under you
NOTE: This library is a work-in-progress. All documentation you see here is subject to change and non-existence.

Usage
Ultimately, the usage looks like this (assuming you have a ZooKeeper server running on your local host):
#include <zk/client.hpp>
#include <zk/multi.hpp>
#include <zk/server/configuration.hpp>
#include <zk/server/server.hpp>
#include <exception>
#include <iostream>
/** All result types are printable for debugging purposes. **/
template <typename T>
void print_thing(const zk::future<T>& result)
{
try
{
// Unwrap the future value, which will not block (based on usage), but could throw.
T value(result.get());
std::cerr << value << std::endl;
}
catch (const std::exception& ex)
{
// Error "handling"
std::cerr << "Exception: " << ex.what() << std::endl;
}
}
int main()
{
// Start a ZK server running on localhost (not needed if you just want a client, but great for testing and
// demonstration purposes).
zk::server::server server(zk::server::configuration::make_minimal("zk-data", 2181));
// zk::client::connect returns a future<zk::client>, which is delivered when the connection is established.
auto client = zk::client::connect("zk://127.0.0.1:2181")
.get();
// get_result has a zk::buffer and zk::stat.
client.get("/foo/bar")
.then(print_thing<zk::get_result>);
// get_children_result has a std::vector<std::string> for the path names and zk::stat for the parent stat.
client.get_children("/foo")
.then(print_thing<zk::get_children_result>);
// set_result has a zk::stat for the modified ZNode.
client.set("/foo/bar", "some data")
.then(print_thing<zk::set_result>);
// More explicit: client.create("/foo/baz", "more data", zk::acls::open_unsafe(), zk::create_mode::normal);
client.create("/foo/baz", "more data")
.then(print_thing<zk::create_result>);
client.get("/foo/bar")
.then([client] (const auto& get_res)
{
zk::version foo_bar_version = get_res.get().stat().data_version;
zk::multi_op txn =
{
zk::op::check("/foo", zk::version::any()),
zk::op::check("/foo/baz", foo_bar_version),
zk::op::create("/foo/bap", "hi", nullopt, zk::create_mode::sequential),
zk::op::erase("/foo/bzr"),
};
// multi_res's type is zk::future<zk::multi_result>
client.commit(txn).then(print_thing<zk::multi_result>);
});
// This is not strictly needed -- a client falling out of scope will auto-trigger close
client.close();
}Value-Added Features
The core library of libzkpp provides the primitives for connecting to and manipulating a ZooKeeper database.
This library also bundles a number of other features that are commonly required when working with a ZooKeeper cluster.
zk/curator
Things in zk/curator have features found in the Apache Curator project.
-
Elections
-
Locks
-
Barriers
-
Counters
-
Caches
-
Nodes
None of the queue types are planned to be implemented. The Curator Documentation (TN4) advises against their use, claiming "it is a bad idea to use ZooKeeper as a Queue." The authors of this library agree with this claim.
zk/fake
This library also provides a fake version of ZooKeeper which operates in-memory.
It is meant to be used in your unit testing, when fine-grained control of behavior of ZooKeeper is needed.
This allows for the injection of arbitrary behavior into ZK, allowing you to simulate some of the hard-to-reproduce
issues like zk::event_type::not_watching, zk::marshalling_error, or timing bugs.
It also allows for fast creation and teardown of entire databases, which is commonly done in unit testing.
It is connected to through using a connection string of the form:
fake://{name}To use this in unit tests link to libzkpp_fake and use zk::fake::server:
TEST(my_test)
{
// The default constructor uses a randomly-generated unique name
zk::fake::server server;
// Fetch that name through the connection_string
zk::client client(server.connection_string());
// use client normally
}zk/server
This library controls a ZooKeeper Java process on this machine. It is meant to be used in applications that manage a ZooKeeper cluster from native code.
Unsupported Functionality
If you are used to using ZooKeeper via the Java or C APIs, there are a few things that are explicitly not supported in this library.
Global Watches
There are two main ways to receive watch notifications: the global watch or through use a watcher objects.
In the Java API, the ZooKeeper client allows for a global
Watcher.
In the C API, zookeeper_init can be provided with a global function with the signature
void (*)(zhandle_t* zh, int type, int state, const char* path, void* watcherCtx) to achieve this same result.
Global watches are somewhat of a "legacy" feature -- the dual interface of global and callbacks is somewhat confusing.
As such, global watches are not supported by this library.
Synchronous API
The C library offers both a synchronous and an asynchronous API.
This library offers only an asynchronous version.
If you prefer a synchronous API, call get() on the returned future to block until you receive the response.
Non-Linux
Can you get this library working on platforms that are not Linux? Maybe. But Linux is the primary development, testing, and deployment platform of people writing distributed applications, so this library is targetted at Linux.
License
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
F.A.Q.
Why erase instead of delete?
In the Java and C APIs, the act of removing a ZNode is called delete and zoo_delete, respectively.
However, delete is a C++ keyword and cannot be used as a member function.
So, this library uses erase, which falls in line with standard C++ containers.
Alternatives such as calling the operation delete_ look a bit worse (in the author's opinion).
Why are watch calls separate?
In the Java and C APIs, adding a watch to a ZNode is an additional parameter to the get, get_children, or exists
calls while this library uses separate watch, watch_children, and watch_exists calls.
This is done because the return types are different between a simple fetch and setting a watch.
While get returns a future<get_result>, watch returns the slightly more complicated future<watch_result>.
The future in watch_result::next() would be disabled in cases where a flag is not set, and it would be ignored with
the majority of use cases.
This leads to an awkward API for simple calls.
An alternative used by other libraries is to provide a std::function, implying to not watch when the function is not
passed in.
This has a number of disadvantages:
- There is no good way to cancel a watch without giving an extra parameter.
With a
future, you simply let it fall out of scope. - Watches are delivered only once, which is obvious from a
future-like API, but not obvious from afunction-like API. - It is not obvious what the behavior should be if the original call returns in error.
With a
future, the behavior is obvious, since you never receive the mechanisms to perform the watch.
In Java, the method of choice is to use the Watcher interface, but this feels extremely out of place in C++ code.
Where are all the KeeperExceptions?
This library uses an exception hierarchy with fewer exception codes than what are available in
KeeperException.
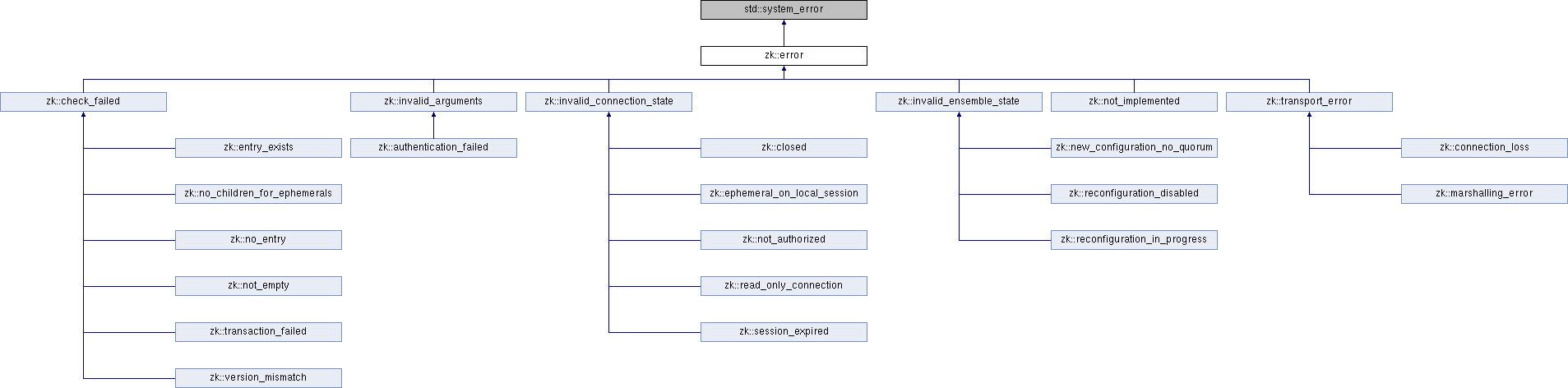
Some exceptions are not present in this library because they are no longer used in the server implementation and will
not be used again; an example of this is DataInconsistencyException, which has not been used in ZooKeeper for a while.
In other cases, the error code would never be thrown by this library; examples of this are NoWatcherException (watch
removal happens implicitly in destructors) and RuntimeInconsistencyException (failed multi-ops throw a
transaction_failed containing only the index of the failed operation instead).
In other cases, the error codes have been merged into a single exception type, as there was much logical overlap.
Another distinction that was dropped is the difference between "system errors" (Code.SYSTEMERROR/ZSYSTEMERROR) and
"API errors" (Code.APIERROR/ZAPIERROR).
The general distinction is the origin of the error -- system errors are client-side (invalid_arguments -- other APIs:
Code.BADARGUMENTS/ZBADARGUMENTS), while API errors are server-size (no_entry -- other APIs:
Code.NoNode/ZNONODE).
This was dropped because this is not entirely meaningful from user's point of view.
As an example, authentication_failed is a subclass of invalid_arguments, even though the contents of the arguments
happen to be validated by the server instead of by the client.
How can I contribute?
Pick an open issue and start working on it! For more details, read the CONTRIBUTING guide.