language-models-are-knowledge-graphs-pytorch
Language models are open knowledge graphs ( work in progress )
A non official reimplementation of Language models are open knowledge graphs
The implemtation of Match is in process.py
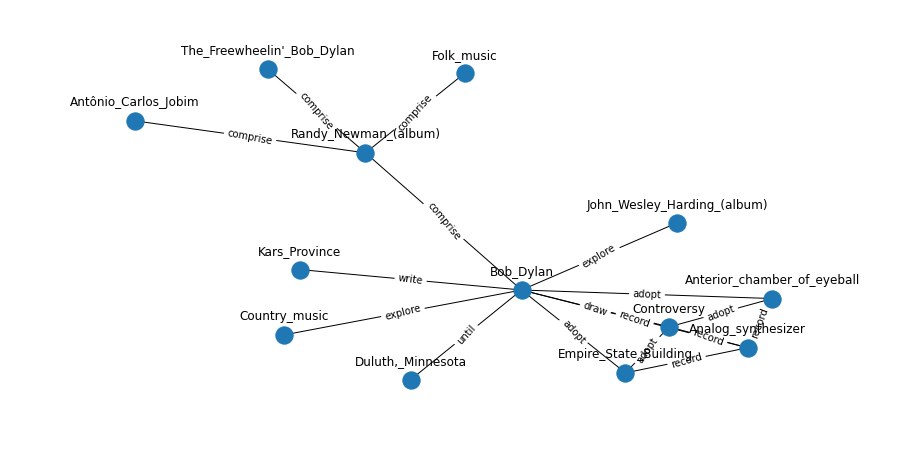
Execute MAMA(Match and Map) section
Do note the extracted results is still quite noisy and should then filtered based on relation unique pair frequency
python extract.py examples/bob_dylan.txt bert-large-cased-bob_dynlan.jsonl --language_model bert-large-cased --use_cuda trueMap
- Entity linking
The original download link for Stanford Entity linking is removed (nlp.stanford.edu/pubs/crosswikis-data.tar.bz2)[nlp.stanford.edu/pubs/crosswikis-data.tar.bz2]. I will use (REL)[https://github.com/informagi/REL] for entity disambiguation model (supervised instead of the original unsupervied) to achieve the same task.
- Relations linking (page 5, 2.2.1)
Lemmatization is done in the previous steps [process.py](), in this stage we remove inflection, auxiliary verbs, adjectives, adverbs words.
Adjectives extracted from here: https://gist.github.com/hugsy/8910dc78d208e40de42deb29e62df913
Adverbs extracted from here : https://raw.githubusercontent.com/janester/mad_libs/master/List%20of%20Adverbs.txt
Environment setup
This repo is run using virtualenv
virtualenv -p python3 env
source env/bin/activate
pip install -r requirements.txt