SAM-Adapter: Adapting SAM in Underperformed Scenes (!!Now Support SAM2 in "SAM2-Adapter" Branch!!)
Tianrun Chen, Lanyun Zhu, Chaotao Ding, Runlong Cao, Yan Wang, Shangzhan Zhang, Zejian Li, Lingyun Sun, Papa Mao, Ying Zang
KOKONI, Moxin Technology (Huzhou) Co., LTD , Zhejiang University, Singapore University of Technology and Design, Huzhou University, Beihang University.
In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 3367-3375).
Update on 8 Aug, 2024: We add support for adapting with SAM2 (Segment Anything 2), a more powerful backbone! Please refer our new technical report! and see the code at "SAM2-Adapter" Branch!
Update on 24 July, 2024: The link of pre-trained model is updated.
Update on 30 August 2023: This paper will be prsented at ICCV 2023.
Update on 28 April 2023: We tested the performance of polyp segmentation to show our approach can also work on medical datasets.
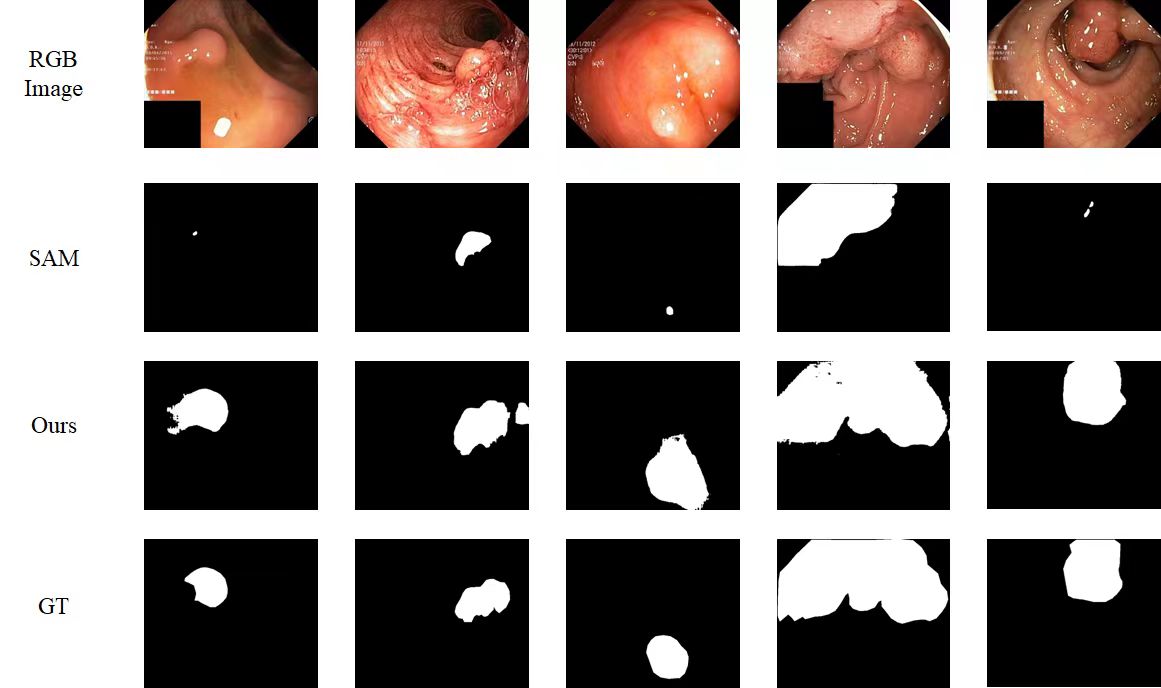
Update on 22 April: We report our SOTA result based on ViT-H version of SAM (use demo.yaml). We have also uploaded the yaml config for ViT-L and ViT-B version of SAM, suitable GPU with smaller memory (e.g. NVIDIA Tesla V-100), although they may compromise on accuracy.
Environment
This code was implemented with Python 3.8 and PyTorch 1.13.0. You can install all the requirements via:
pip install -r requirements.txtQuick Start
-
Download the dataset and put it in ./load.
-
Download the pre-trained SAM(Segment Anything) and put it in ./pretrained.
-
Training:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nnodes 1 --nproc_per_node 4 loadddptrain.py --config configs/demo.yaml!Please note that the SAM model consume much memory. We use 4 x A100 graphics card for training. If you encounter the memory issue, please try to use graphics cards with larger memory!
-
Evaluation:
python test.py --config [CONFIG_PATH] --model [MODEL_PATH]
Train
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch train.py --nnodes 1 --nproc_per_node 4 --config [CONFIG_PATH]Updates on 30 July. As mentioned by @YunyaGaoTree in issue #39 You can also try to use the code below to gain (probably) faster training.
!torchrun train.py --config configs/demo.yaml
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nnodes 1 --nproc_per_node 4 loadddptrain.py --config configs/demo.yamlTest
python test.py --config [CONFIG_PATH] --model [MODEL_PATH]Pre-trained Models
https://drive.google.com/file/d/13JilJT7dhxwMIgcdtnvdzr08vcbREFlR/view?usp=sharing
Dataset
Camouflaged Object Detection
Shadow Detection
Polyp Segmentation - Medical Applications
Citation
If you find our work useful in your research, please consider citing:
@inproceedings{chen2023sam,
title={Sam-adapter: Adapting segment anything in underperformed scenes},
author={Chen, Tianrun and Zhu, Lanyun and Deng, Chaotao and Cao, Runlong and Wang, Yan and Zhang, Shangzhan and Li, Zejian and Sun, Lingyun and Zang, Ying and Mao, Papa},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={3367--3375},
year={2023}
}
@misc{chen2024sam2adapterevaluatingadapting,
title={SAM2-Adapter: Evaluating & Adapting Segment Anything 2 in Downstream Tasks: Camouflage, Shadow, Medical Image Segmentation, and More},
author={Tianrun Chen and Ankang Lu and Lanyun Zhu and Chaotao Ding and Chunan Yu and Deyi Ji and Zejian Li and Lingyun Sun and Papa Mao and Ying Zang},
year={2024},
eprint={2408.04579},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.04579},
}
@misc{chen2023sam,
title={SAM Fails to Segment Anything? -- SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, and More},
author={Tianrun Chen and Lanyun Zhu and Chaotao Ding and Runlong Cao and Shangzhan Zhang and Yan Wang and Zejian Li and Lingyun Sun and Papa Mao and Ying Zang},
year={2023},
eprint={2304.09148},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Acknowledgements
The part of the code is derived from Explicit Visual Prompt by
Weihuang Liu, Xi Shen, Chi-Man Pun, and Xiaodong Cun by University of Macau and Tencent AI Lab.