Facebook_Crawler
What's this?
This python package aims to help people who need to collect and analyze the public Fanspages or Groups data from Facebook with ease and efficiency.
Here are the three big points of this project:
- Private: You don't need to log in to your account.
- Easy: Just key in the link of Fanspage or group and the target date, and it will work.
- Efficient: It collects the data through the requests package directly instead of opening another browser.
這個 Python 套件旨在幫助使用者輕鬆且快速的收集 Facebook 公開粉絲頁和公開社團的資料,藉以進行後續的分析。
以下是本專案的 3 個重點:
- 隱私: 不需要登入你個人的帳號密碼
- 簡單: 僅需輸入粉絲頁/社團的網址和停止的日期就可以開始執行程式
- 高效: 透過 requests 直接向伺服器請求資料,不需另外開啟一個新的瀏覽器
Quickstart
Install
pip install -U facebook-crawlerUsage
-
Facebook Fanspage
import facebook_crawler pageurl= 'https://www.facebook.com/diudiu333' facebook_crawler.Crawl_PagePosts(pageurl=pageurl, until_date='2021-01-01')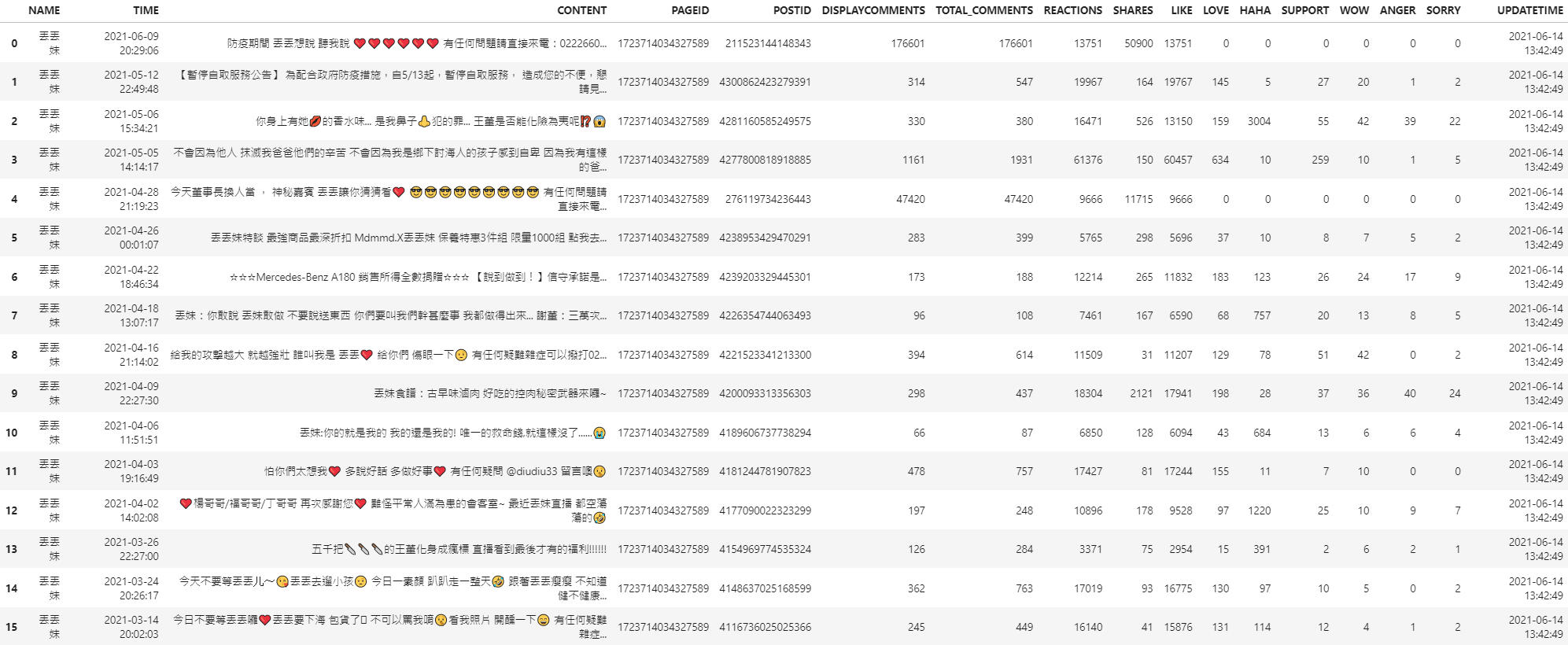
-
Group
import facebook_crawler groupurl = 'https://www.facebook.com/groups/pythontw' facebook_crawler.Crawl_GroupPosts(groupurl, until_date='2021-01-01')
FAQ
-
How to get the comments or replies to the posts?
Please write an Email to me and tell me your project goal. Thanks!
-
How can I find out the post's link through the data?
You can add the string 'https://www.facebook.com' in front of the POSTID, and it's just its post link. So, for example, if the POSTID is 123456789, and its link is 'https://www.facebook.com/12345679'.
-
Can I directly collect the data in the specific time period?
No! This is the same as the behavior when we use Facebook. We need to collect the data from the newest posts to the older posts.
License
Contribution

A donation is not the limitation to utilizing this package, but it would be great to have your support. Either donate, star or fork are good methods to support me keep maintaining and developing this project.
Thanks to these donors' help, due to their kind help, this project could keep maintained and developed.
贊助不是使用這個套件的必要條件,但如能獲得你的支持我將會非常感謝。不論是贊助、給予星星或分享都是很好的支持方式,幫助我繼續維護和開發這個專案
由於這些捐助者的幫助,由於他們的慷慨的幫助,這個項目才得以持續維護和發展
- Universities
Contact Info
- Author: TENG-LIN YU
- Email: tlyu0419@gmail.com
- Facebook: https://www.facebook.com/tlyu0419
- PYPI: https://pypi.org/project/facebook-crawler/
- Github: https://github.com/TLYu0419/facebook_crawler
Log
- 0.028: Modularized the crawler function.
- 0.0.26
- Auto changes the cookie after it's expired to keep crawling data without changing IP.