paretoset 



Compute the Pareto (non-dominated) set, i.e., skyline operator/query.
Watch the YouTube video: Analyzing data with the Pareto set
Installation
The software is available through GitHub, and through PyPI.
You may install the software using pip:
pip install paretosetExamples - Skyline queries for data analysis and insight
Hotels that are cheap and close to the beach
In the database context, the Pareto set is called the skyline and computing the Pareto set is called a skyline query. The folllowing example is from the paper "The Skyline Operator" by Börzsönyi et al.
Suppose you are going on holiday and you are looking for a hotel that is cheap and close to the beach. These two goals are complementary as the hotels near the beach tend to be more expensive. The database system is unable to decide which hotel is best for you, but it can at least present you all interesting hotels. Interesting are all hotels that are not worse than any other hotel in both dimensions. You can now make your final decision, weighing your personal preferences for price and distance to the beach.
Here's an example showing hotels in the Pareto set.
from paretoset import paretoset
import pandas as pd
hotels = pd.DataFrame({"price": [50, 53, 62, 87, 83, 39, 60, 44],
"distance_to_beach": [13, 21, 19, 13, 5, 22, 22, 25]})
mask = paretoset(hotels, sense=["min", "min"])
paretoset_hotels = hotels[mask]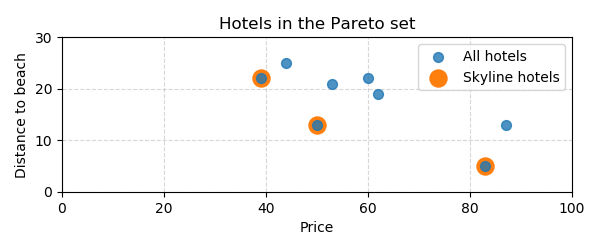
Top performing salespeople
Suppose you wish to query a database for salespeople that might be eligible for a raise. To find top performers (low salary, but high sales) for every department:
from paretoset import paretoset
import pandas as pd
salespeople = pd.DataFrame(
{
"salary": [94, 107, 67, 87, 153, 62, 43, 115, 78, 77, 119, 127],
"sales": [123, 72, 80, 40, 64, 104, 106, 135, 61, 81, 162, 60],
"department": ["c", "c", "c", "b", "b", "a", "a", "c", "b", "a", "b", "a"],
}
)
mask = paretoset(salespeople, sense=["min", "max", "diff"])
top_performers = salespeople[mask]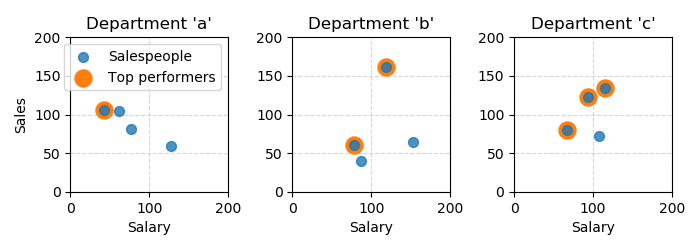
Example - Pareto efficient solutions in multiobjective optimization
Suppose you wish to query a database for salespeople that might be eligible for a raise. To find top performers (low salary, but high sales) for every department:
from paretoset import paretoset
import numpy as np
from collections import namedtuple
# Create Solution objects holding the problem solution and objective values
Solution = namedtuple("Solution", ["solution", "obj_value"])
solutions = [Solution(solution=object, obj_value=np.random.randn(2)) for _ in range(999)]
# Create an array of shape (solutions, objectives) and compute the non-dominated set
objective_values_array = np.vstack([s.obj_value for s in solutions])
mask = paretoset(objective_values_array, sense=["min", "max"])
# Filter the list of solutions, keeping only the non-dominated solutions
efficient_solutions = [solution for (solution, m) in zip(solutions, mask) if m]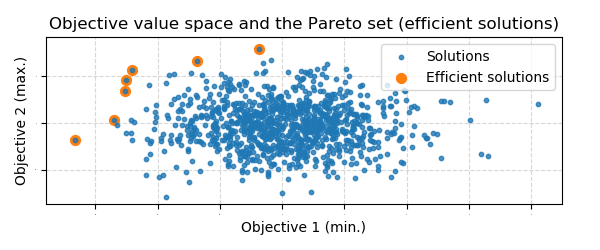
Contributing
You are very welcome to scrutinize the code and make pull requests if you have suggestions and improvements. Your submitted code must be PEP8 compliant, and all tests must pass.
Contributors: Kartik
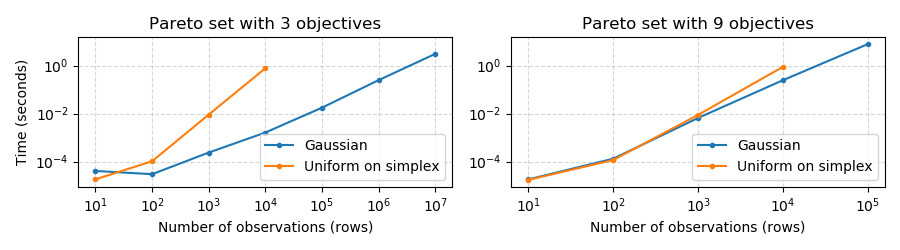
Performance
The graph below shows how long it takes to compute the Pareto set. Gaussian data has only a few observations in the Pareto set, while uniformly distributed data on a simplex has every observations in the Pareto set.
References
- "The Skyline Operator" by Börzsönyi et al. introduces the Skyline Operator in the database context.