Rikolti
Calisphere harvester 2.0: Rikolti is the name for a collection of components designed to work together to aggregate metadata records from Calisphere's contributing institutions (Metadata Fetcher), normalize the metadata to a standard schema (Metadata Mapper), augment with supporting content files (Content Fetcher), and index for searching (Indexer).
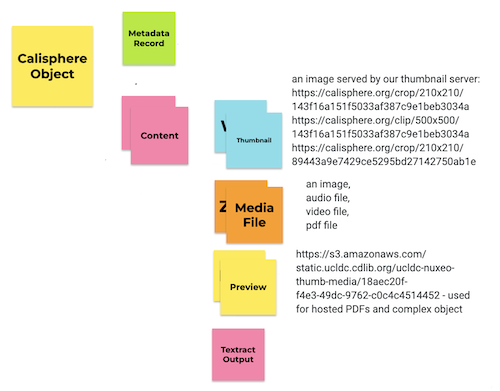
A Calisphere object is generally composed of metadata (sometimes called the metadata record) and content. Metadata is, explicitly, the metadata record fetched from the source institution and then mapped to the UCLDC schema. Content comes in several flavors depending on the type of object (text, audio, video, image, etc) and Calisphere's relationship to the contributing institution - we differentiate between harvesting from our own CDL-hosted Nuxeo digital asset management system (hosted objects) and harvesting from external systems (harvested objects). Content almost always includes a thumbnail - exceptions include audio objects harvested from external systems. Content can also include a media file if the object is hosted in the Nuxeo digital asset management system. Content can further include a preview if the object is hosted in Nuxeo and is a pdf, or if the object is hosted in Nuxeo and is part of a complex object. This structure is recursive: in the case of hosted complex objects, content may also include an ordered list of objects. This structure will likely also evolve to include additional pieces of data, for example, content may, in the future, include textract output of PDF media file analysis.
Each folder in this repository corresponds to a separate component of the Rikolti data pipeline. As of this writing on November 14th, 2022, metadata_fetcher and metadata_mapper are the most developed, while the others are left over from an earlier prototype.
Development
Getting Started
Clone the repository. This documentation assumes you've cloned into ~/Projects/.
cd ~/Projects/
git clone git@github.com:ucldc/rikolti.gitOSX
Set up a python environment using python version 3.9. I'm working on a mac with a bash shell. I use pyenv to manage python versions and I use python3 venv to manage a python virtual environment located in ~/.venv/rikolti/. The following commands are meant to serve as a guide - please check the installation instructions for pyenv for your own environment.
# install pyenv
brew update
brew install pyenv
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
source ~/.bash_profile
# install python3.9 and set it as the local version
pyenv install 3.9
cd ~/Projects/rikolti/
pyenv local 3.9
python --version
# > Python 3.9.15
# create python virtual environment
python -m venv .venv/rikolti/
source .venv/rikolti/bin/activate
# install dependencies
pip install -r requirements_dev.txt
# setup local environment variables
cp env.example env.local
vi env.localCurrently, I only use one virtual environment, even though each folder located at the root of this repository represents an isolated component. If dependency conflicts are encountered, I'll wind up creating separate environments.
Similarly, I also only use one env.local as well. Rikolti fetches data to your local system, maps that data, and then fetches relevant content files (media files, previews, and thumbnails). Set VERNACULAR_DATA to the URI where you would like Rikolti to store and retrieve fetched data - Rikolti will create a folder (or s3 prefix) <collection_id>/vernacular_metadata at this location. Set MAPPED_DATA to the URI where you would like Rikolti to store and retrieve mapped data - Rikolti will create a folder (or s3 prefix) <collection_id>/mapped_metadata at this location. Set WITH_CONTENT_URL_DATA to the URI where you would like Rikolti to store mapped data that has been updated with urls to content files - Rikolti will create a folder (or s3 prefix) <collection_id>/with_content_urls at this location. Set CONTENT_ROOT to the URI where you would like Rikolti to store content files.
For example, one way to configure env.local is:
VERNACULAR_DATA=file:///Users/awieliczka/Projects/rikolti/rikolti_data
MAPPED_DATA=$VERNACULAR_DATA
WITH_CONTENT_URL_DATA=$VERNACULAR_DATA
CONTENT_ROOT=file:///Users/awieliczka/Projects/rikolti/rikolti_contentEach of these can be different locations, however. For example, if you're attempting to re-run a mapper locally off of previously fetched data stored on s3, you might set VERNACULAR_DATA=s3://rikolti_data.
In env.example you'll also see METADATA_MOUNT and CONTENT_MOUNT environment variables. These are only relevant if you are running the content harvester using airflow, and want to set and of the CONTENT_ environment variables to the local filesystem. Their usage is described below in the Airflow Development section.
Docker
After cloning the repo, run script/up to build and start the container. The
container will continue running until stopped. As most development tasks take place in
the Python console, there are two commands for starting the console with
metadata_fetcher or metadata_mapper modules imported. They are:
bin/map - starts the console with the mapper modules imported
bin/fetch - starts the console with the fetcher modules imported
Additionally, there is:
bin/console - starts with console without importing fetcher or mapper modules
These commands install pip requirements and start an ipython console session.
The autoreload ipython extension is automatically loaded. Typing
autoreload or, just r in the console with reload all loaded modules.
To run other commands in the container, run docker compose exec from the
project root:
docker compose exec python ls -al
Development Contribution Process
The Rikolti Wiki contains lots of helpful technical information. The GitHub Issues tool tracks Rikolti development tasks. We organize issues using the GitHub project board Rikolti MVP to separate work out into Milestones and Sprints.
All work should be represented by an issue or set of issues. Please create an issue if one does not exist. In order for our project management processes to function smoothly, when creating a new issue, please be sure to include any relevant Assignees, Projects ("Rikolti MVP"), Milestones, and Sprints.
We use development branches with descriptive names when working on a particular issue or set of issues. Including issue numbers or exact issue names is not necessary. Please use a distinct branch for a distinct piece of work. For example, there should be one development branch for a fetcher, and a different development branch for a mapper - even if the work for the mapper is dependent on the fetcher (you may create a mapper branch with the fetcher branch as the basis).
When starting work on a given issue, please indicate the date started. If more information is needed to start work on an issue, please @ CDL staff.
When finishing work on a given issue:
- Create a pull request to the main branch for a code owner to review. Be sure to link the pull request to the issue or set of issues it addresses, and add any relevant Projects ("Rikolti MVP"), Milestones, and Sprints.
- Indicate on the issue the date delivered, and move the issue to the "Ready for Review" state.
We use PR reviews to approve or reject, comment on, and request further iteration. It's the contributor's responsibility to keep their development branches up-to-date with main (or any other designated upstream branches).
Code Style Guide
- PEP 8 (enforced using flake8)
- Readability & Transparency: Code as language
- Favor explicitness over defensiveness
- Import statements grouped according to isort defaults:
- FUTURE
- STDLIB
- THIRDPARTY
- FIRSTPARTY
- LOCALFOLDER
Dags
Dags that use the rikolti modules in Airflow are defined in the dags folder.
A very basic level of testing is done on the dags to ensure tey load as expected.
Continuous Deployment
On each merge to main, an AWS CodeBuild task will run, triggered by a webhook emitted from github that the CodeBuild project listens for.
Airflow Development
Set up aws-mwaa-local-runner
AWS provides the aws-mwaa-local-runner repo, which provides a command line interface (CLI) utility that replicates an Amazon Managed Workflows for Apache Airflow (MWAA) environment locally via use of a Docker container. We have forked this repository and made some small changes to enable us to use local-runner while keeping our dags stored in this repository. (See this slack thread for more info: https://apache-airflow.slack.com/archives/CCRR5EBA7/p1690405849653759)
To set up the airflow dev environment, clone the repo locally:
git clone git@github.com:ucldc/aws-mwaa-local-runner.gitThen, copy aws-mwaa-local-runner/docker/.env.example:
cp aws-mwaa-local-runner/docker/.env.example aws-mwaa-local-runner/docker/.envIf you have not already, you should also clone the rikolti repo locally.
Note: The location of the Rikolti repo relative to the aws-mwaa-local-runner repo does not matter - we will configure some environment variables so the aws-mwaa-local-runner can find Rikolti.
git clone git@github.com:ucldc/rikolti.gitBack in aws-mwaa-local-runner/docker/.env, set the following env vars to wherever you have cloned the rikolti repository, for example:
DAGS_HOME="/Users/username/dev/rikolti"
PLUGINS_HOME="/Users/username/dev/rikolti/plugins"
REQS_HOME="/Users/username/dev/rikolti/dags"
STARTUP_HOME="/Users/username/dev/rikolti/dags"
RIKOLTI_DATA_HOME="/Users/username/dev/rikolti_data"
DOCKER_SOCKET="/var/run/docker.sock"These env vars are used in the aws-mwaa-local-runner/docker/docker-compose-local.yml script (and other docker-compose scripts) to mount the relevant directories containing Airflow DAGs, requirements, plugin files, startup file, Rikolti data destination, and docker socket into the docker container.
The docker socket will typically be at /var/run/docker.sock. On Mac OS Docker Desktop you can check that the socket is available and at this location by opening Docker Desktop's settings, looking under "Advanced", and checking the "Allow the Docker socket to be used" setting.
Next, back in the Rikolti repository, create the startup.sh file by running cp env.example dags/startup.sh. Update the startup.sh file with Nuxeo, Flickr, and Solr keys as available, and make sure that the following environment variables are set:
export VERNACULAR_DATA=file:///usr/local/airflow/rikolti_data
export MAPPED_DATA=file:///usr/local/airflow/rikolti_data
export WITH_CONTENT_URL_DATA=file:///usr/local/airflow/rikolti_data
export MERGED_DATA=file:///usr/local/airflow/rikolti_dataThe folder located at RIKOLTI_DATA_HOME (set in aws-mwaa-local-runner/docker/.env) is mounted to /usr/local/airflow/rikolti_data on the airflow docker container.
Please also make sure the following variables are set - METADATA_MOUNT and CONTENT_MOUNT to wherever the rikolti_data and rikolti_content folders live on your local machine, for example:
export METADATA_MOUNT=/Users/awieliczka/Projects/rikolti_data
export CONTENT_MOUNT=/Users/awieliczka/Projects/rikolti_contentThe folder located at METADATA_MOUNT is mounted to /rikolti_data and the folder located at CONTENT_MOUNT is mounted to /rikolti_content on the content_harvester docker container.
You can specify a CONTENT_HARVEST_IMAGE and CONTENT_HARVEST_VERSION through environment variables as well. The default value for CONTENT_HARVEST_IMAGE is public.ecr.aws/b6c7x7s4/rikolti/content_harvester and the default value for CONTENT_HARVEST_VERSION is latest.
If you would like to run the content harvester on AWS infrastructure using the ECS operator, or if you are deploying Rikolti to MWAA, you can specify CONTAINER_EXECUTION_ENVIRONMENT='ecs' (you'll need some AWS credentials as well). The CONTAINER_EXECUTION_ENVIRONMENT is, by default, a docker execution environment.
A note about Docker vs. ECS: Since we do not actively maintain our own Docker daemon, and since MWAA workers do not come with a Docker daemon installed, we cannot use a docker execution environment in deployed MWAA and instead use ECS to run our content harvester containers on Fargate infrastructure. The EcsRunTaskOperator allows us to run a pre-defined ECS Task Definition. The EcsRegisterTaskDefinitionOperator allows us to define an ECS Task Definition which we could then run. At this time, we are defining the Task Definition in our cloudformation templates, rather than using the EcsRegisterTaskDefinitionOperator, but this does mean that we cannot modify the container's image or version using the EcsRunTaskOperator.
If you would like to run your own rikolti/content_harvester image instead of pulling the image from AWS, then from inside the Rikolti repo, run docker build -f Dockerfile.content_harvester -t rikolti/content_harvester . to build the rikolti/content_harvester image locally and add the following line to dags/startup.sh to update CONTENT_HARVEST_IMAGE to be rikolt/content_harvester:
export CONTENT_HARVEST_IMAGE=rikolti/content_harvesterIf you would like to mount your own codebase to the content_harvester container run via a DockerOperator in Airflow, then add the following to dags/startup.sh:
export MOUNT_CODEBASE=<path to rikolti, for example: /Users/awieliczka/Projects/rikolti>In order to run the indexer code against an AWS hosted OpenSearch, make sure the following variables are set in startup.sh:
export OPENSEARCH_ENDPOINT= # ask for endpoint url
export AWS_ACCESS_KEY_ID=
export AWS_SECRET_ACCESS_KEY=
export AWS_SESSION_TOKEN=
export AWS_REGION=us-west-2If using a local Docker container to run a dev OpenSearch, set the following variables in startup.sh:
export OPENSEARCH_ENDPOINT=https://host.docker.internal:9200/
export OPENSEARCH_USER=admin
export OPENSEARCH_PASS="Rikolti_05"
export OPENSEARCH_IGNORE_TLS=TrueFinally, from inside the aws-mwaa-local-runner repo, run ./mwaa-local-env build-image to build the docker image, and ./mwaa-local-env start to start the mwaa local environment.
For more information on mwaa-local-env, look for instructions in the ucldc/aws-mwaa-local-runner:README to build the docker image, run the container, and do local development.
Upgrade aws-mwaa-local-runner
To upgrade:
- In the
ucldc/aws-mwaa-local-runnerrepo, create a new branch for the new version. The upstream source should beaws/aws-mwaa-local-runner. I just used the github UI to do this at https://github.com/ucldc/aws-mwaa-local-runner/branches - On your local machine, pull down and checkout this new branch.
- Merge in our commits from the old version branch.
- In your local
rikoltirepo, updaterikolti/dags/requirements.txtto reference the correct --constraint url. - Build mwaa-local-runner and test out DAGs in v2.6.3 to make sure all is well.
- Update
aws-mwaa-local-runner/.github/workflows/pull_upstream.ymland set UPSTREAM_BRANCH to new version. - Commit changes to
aws-mwaa-local-runnerrepo and push to github. - Change default branch for
ucldc/aws-mwaa-local-runnerto be the new version's branch. (I just used the github UI to do this). - Commit changes to
rikoltirepo and push to github.
NOTE: Pushing to the rikolti main branch on github will trigger a build of the rikolti-dags-deploy project, which pushes all .py files in the rikolti repo to s3:pad-airflow/dags/rikolti/. This will NOT update the requirements.txt version for our MWAA environment on AWS. You will need to do this as part of upgrading MWAA. Notes on how to do this are on the pad-airflow README.