Generative Negative Mining
Project Page | Model Checkpoint | Dataset
This is the official implementation for the paper [ Enhancing Multimodal Compositional Reasoning of Visual Language Models with Generative Negative Mining](). We propose a framework that not only mines in both directions but also generates challenging negative samples in both modalities, i.e., images and texts. Leveraging these generative hard negative samples, we significantly enhance VLMs’ performance in tasks involving multimodal compositional reasoning.
Installation
Requirements: python>=3.8, cuda=11.3
git clone https://github.com/ugorsahin/Generative-Negative-Mining
cd Generative-Negative-Mining
pip install -r requirements.txtWe advise installing on a virtual environment to avoid library dependency crashes.
Data Generation
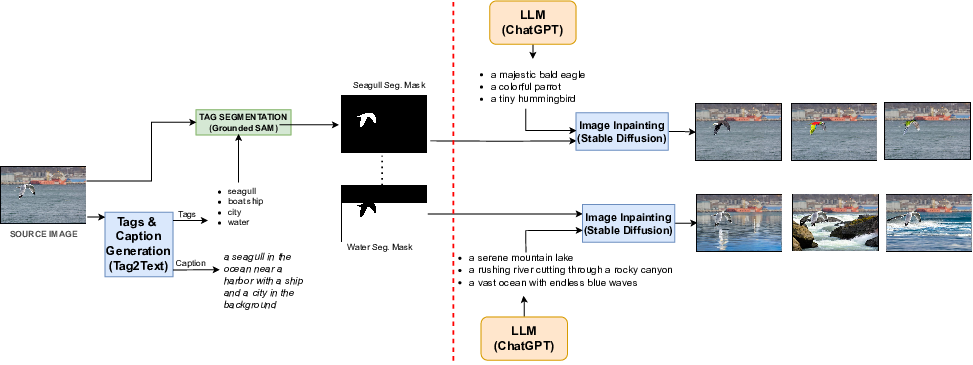
The semi-synthetic variations can be generated stage-by-stage or by using the pipeline script (if you don't have enough gpu memory)
To run the pipeline
- Change into directory
generation_pipelineby usingcd generation_pipeline - Run the script as follows
python pipeline.py \ --tag2text-checkpoint=<path/to/tag2text_model> \ --gd-config=<path/to/gd_config> \ --gd-checkpoint=<path/to/gd_checkpoint> \ --sam-checkpoint=<path/to/sam_checkpoint> \ --sd-checkpoint=<path/to/sd_checkpoint> \ --output-dir=<path/to/output> \ --input-dir=<path/to/images> \ --root-dir=<path/to/root>
Train
To train the clip
- Change into directory
trainingby usingcd training - Run the following code.
python train.py --epoch=<number_of_epochs> \ --mode='allinone|item_based|image_based' \ --save-path=<path/to/save_folder> \ --dataset=<path/to/variation_dataset> \ --image-root=<path/to/image_root> \ --coco-dataset=<path/to/coco_dataset> \ --coco-image_dir=<path/to/coco_images> \
Evaluation
To evaluate the model checkpoints
-
- Change into directory
evaluationby usingcd evaluationpython eval_autogmentation.py \ --model-name=<tag-for-your-model> \ --snapshot_file=<specify if you want to evaluate one model>' \ --snapshot_folder=<specify if you want to evaluate all training>' --evaluation-filepath=<path/to/evaluation_annotations> \ --evaluation-image-folder=<path/to/eval/images>
- Change into directory
- Either set snapshot-file or snapshot-folder
Resources
Training annotation file (.json)
Citation
If you find our work helpful in your research, please consider citing us
@misc{sahin2023enhancing,
title={Enhancing Multimodal Compositional Reasoning of Visual Language Models with Generative Negative Mining},
author={Ugur Sahin and Hang Li and Qadeer Khan and Daniel Cremers and Volker Tresp},
year={2023},
eprint={2311.03964},
archivePrefix={arXiv},
primaryClass={cs.CV},
journal = {Winter Conference on Applications of Computer Vision},
}