trytes
This project is currently discussing how to convert between trytes and bytes in a good way, that may be implemented in most programming languages.
Currently this project does not contain any has now code for encoding trytes and bytes.\
That might change.
It contains a JavaScript example for:
- encoding/decoding 'tryte3 strings' as bytes
- encoding/decoding bytes as 'tryte6 strings' (Why is this not the same? See below.)
- encoding/decoding unicode text as 'tryte6 strings'
Live demo can be seen on [[https://vbakke.github.io/trytes/]].
What's a tryte?
People don't agree.\ Some treat 3 trits as a tryte.\ Some treat 5 trits as a tryte.\ Some treat 6 trits as a tryte.\ (Just as there were 7-bits and 8-bits bytes at the beginning of time.)
Here we'll use the tryte3, tryte5 and tryte6 to indicate which tryte we are talking about.
Installation
npm install trytes
Usage
Further below, you will find out why we need six different function to convert between bytes and trytes. It all depends on what is the original, native, form of your data.
Text or unicode strings
If you have a text string, use the following:
const Trytes = require('trytes');
// Native text, encoded as tryte strings
let trytes = Trytes.encodeTextAsTryteString('hi'); // -> "WCXC"
let str = Trytes.decodeTextFromTryteString("WCXC"); // -> "hi"
trytes = Trytes.encodeTextAsTryteString('Säφę'); // -> "YYBCFGBFRGZDGGRE"
trytes = Trytes.encodeTextAsTryteString('雪หิ🌲☃'); // -> "YZRHOEPAN9YAN9FB9HWAGHC9KA"In JavaScript, the text strings are all in Unicode UTF-16 internally. The tryte string is encoded using ANSI, UTF-8 or UTF-16 depending on what gives the shortest tryte string. You normally won't need to think about it.
Raw bytes
If you have raw byte values, all the Unicode magic should be avoided. Use the following.
const Trytes = require('trytes');
// Native bytes, encoded as tryte strings
let trytes = Trytes.encodeBytesAsTryteString([0x00, 0xFF]); // -> "99LI"
let bytes = Trytes.decodeBytesFromTryteString("99LI"); // -> Array(2) [0, 255]
Tryte strings
If you have a native tryte string, such as an IOTA seed or address, you need to use the following.
const Trytes = require('trytes');
// Native trytes, encoded as bytes
let bytes = Trytes.encodeTryteStringAsBytes("99IZZ"); // -> Uint8Array(4) [0, 189, 242]
let trytes = Trytes.decodeTryteStringFromBytes([0, 189, 242]); // -> "99IZZ"Five tryte3 are combined into three tryte5, and then converted to byte8. A padding byte is included when the number of tryte3 cannot be divided by 5, to decode the length correctly.
How do we fit the square peg in the round hole?
When trying to convert between binary and trinary, we try to fit square pegs in round holes, as well as the round pegs in the square holes.

There's going to be some wasted space, no matter how we solve this.
If you want to convert, you have to go to a "bigger bucket".\ One cannot convert into a "smaller bucket", if the whole range is being used.
Byte <-> tryte conversion
Formats and values
This is important: Just as a byte does not contain a hex value;\ a tryte never contains a letter from A-Z, nor a 9.
Both a byte and a tryte contain values. A number.\
That number may be written as 'A', '0x41', '65', '\0101', 'KB'.\
That's the formatting. The value is still 65.
In other words: 'KB' is not really a tryte.\
'KB' is a way we write the tryte value 65.
Why not just byte2tryte() and tryte2byte()?
Because they won't fit. Not both ways.
A byte8 can be converted into a tryte6 (or two-letter tryte in IOTA). But we will never use all the values in the tryte. We will never get higher than 255 (which may be written 'LI' in the tryte way). We will never get tryte pairs from 'MI' to 'ZZ'.
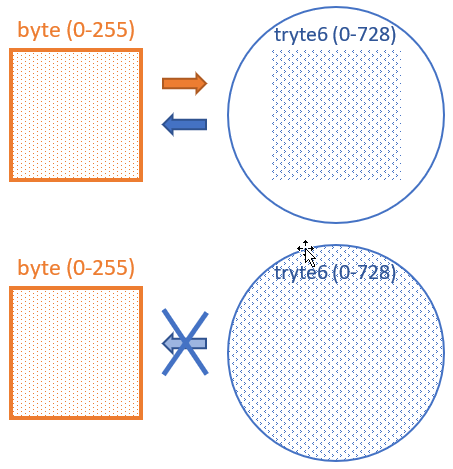
This applies for all conversion between binary and trinary. The buckets have different sizes. You can pour a litre into a gallon. And as long as you don't add more water, you can pour it back into the original bucket.
But you cannot pour a full gallon into a litre.
If you buy a 10L bucket, you can pour a gallon into it. But never a full 10L into a gallon. It's a race you'll never win.
Conclusion
I see no way around this problem, but to have specific function depending on the size of the original information.
You'd normally start with bytes or text strings that you want into trytes for a transaction, before reverting it back.
Or you start with tryte strings that you want to have in binary, before reverting it back to trytes.
"Convert"
In my ears, the word "convert" sound like you can convert both ways. I have chosen to avoid this term in the API, and rather use "encode" and "decode".
Feel free to suggest better names. : )