Label-Efficient Semantic Segmentation with Diffusion Models
ICLR'2022 [Project page]
Official implementation of the paper Label-Efficient Semantic Segmentation with Diffusion Models
This code is based on datasetGAN and guided-diffusion.
Note: use --recurse-submodules when clone.
Overview
The paper investigates the representations learned by the state-of-the-art DDPMs and shows that they capture high-level semantic information valuable for downstream vision tasks. We design a simple semantic segmentation approach that exploits these representations and outperforms the alternatives in the few-shot operating point.
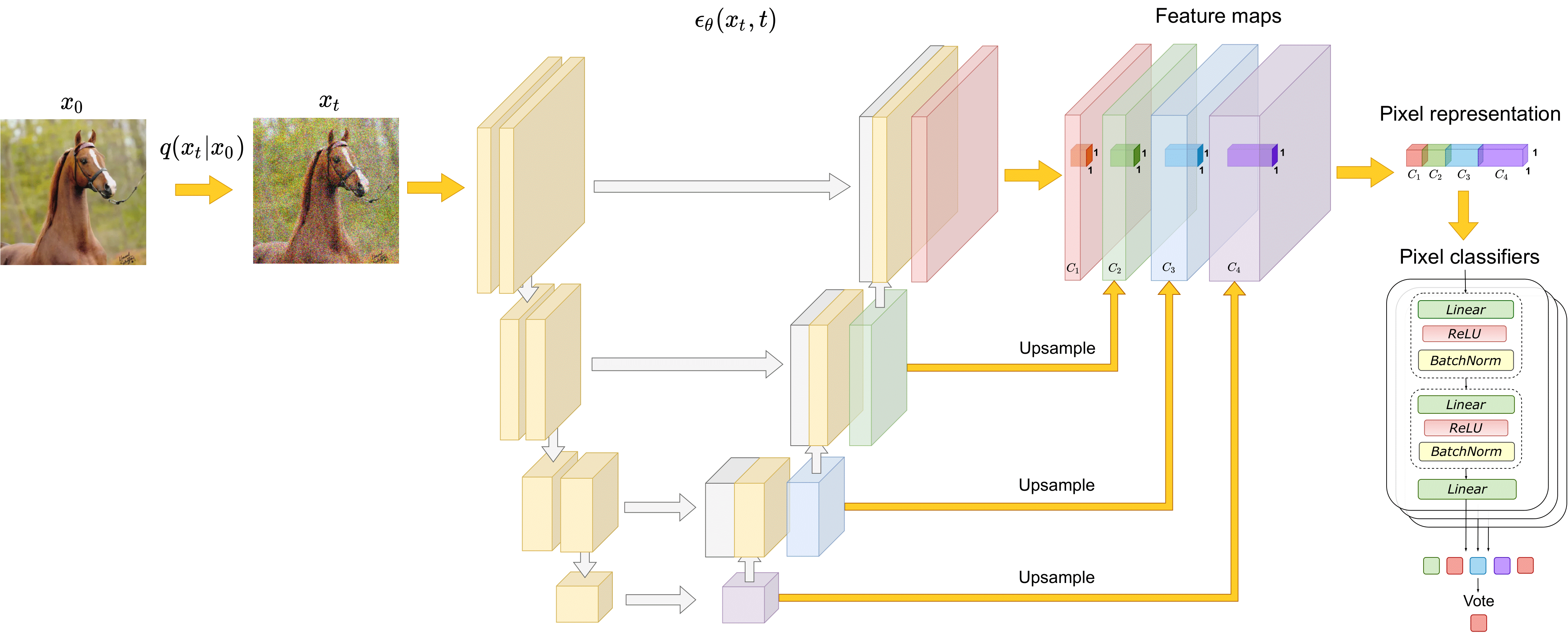
Updates
3/9/2022:
1) Improved performance of DDPM-based segmentation by changing:\ Diffusion steps: [50,150,250,350] --> [50,150,250];\ UNet blocks: [6,7,8,9] --> [5,6,7,8,12]; 3) Trained a bit better DDPM on FFHQ-256; 4) Added MAE for comparison.
Datasets
The evaluation is performed on 6 collected datasets with a few annotated images in the training set: Bedroom-18, FFHQ-34, Cat-15, Horse-21, CelebA-19 and ADE-Bedroom-30. The number corresponds to the number of semantic classes.
datasets.tar.gz (~47Mb)
DDPM
Pretrained DDPMs
The models trained on LSUN are adopted from guided-diffusion. FFHQ-256 is trained by ourselves using the same model parameters as for the LSUN models.
LSUN-Bedroom: lsun_bedroom.pt\ FFHQ-256: ffhq.pt (Updated 3/8/2022)\ LSUN-Cat: lsun_cat.pt\ LSUN-Horse: lsun_horse.pt
Run
- Download the datasets:\
bash datasets/download_datasets.sh - Download the DDPM checkpoint:\
bash checkpoints/ddpm/download_checkpoint.sh <checkpoint_name> - Check paths in
experiments/<dataset_name>/ddpm.json - Run:
bash scripts/ddpm/train_interpreter.sh <dataset_name>
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse\ Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21, celeba_19, ade_bedroom_30
Note: train_interpreter.sh is RAM consuming since it keeps all training pixel representations in memory. For ex, it requires ~210Gb for 50 training images of 256x256. (See issue)
Pretrained pixel classifiers and test predictions are here.
How to improve the performance
- Tune for a particular task what diffusion steps and UNet blocks to use.
DatasetDDPM
Synthetic datasets
To download DDPM-produced synthetic datasets (50000 samples, ~7Gb) (updated 3/8/2022):\
bash synthetic-datasets/ddpm/download_synthetic_dataset.sh <dataset_name>
Run | Option #1
- Download the synthetic dataset:\
bash synthetic-datasets/ddpm/download_synthetic_dataset.sh <dataset_name> - Check paths in
experiments/<dataset_name>/datasetDDPM.json - Run:
bash scripts/datasetDDPM/train_deeplab.sh <dataset_name>
Run | Option #2
-
Download the datasets:\
bash datasets/download_datasets.sh -
Download the DDPM checkpoint:\
bash checkpoints/ddpm/download_checkpoint.sh <checkpoint_name> -
Check paths in
experiments/<dataset_name>/datasetDDPM.json -
Train an interpreter on a few DDPM-produced annotated samples:\
bash scripts/datasetDDPM/train_interpreter.sh <dataset_name> -
Generate a synthetic dataset:\
bash scripts/datasetDDPM/generate_dataset.sh <dataset_name>\ Please specify the hyperparameters in this script for the available resources.\ On 8xA100 80Gb, it takes about 12 hours to generate 10000 samples. -
Run:
bash scripts/datasetDDPM/train_deeplab.sh <dataset_name>\ One needs to specify the path to the generated data. See comments in the script.
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse\ Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21
MAE
Pretrained MAEs
We pretrain MAE models using the official implementation on the LSUN and FFHQ-256 datasets:
LSUN-Bedroom: lsun_bedroom.pth\ FFHQ-256: ffhq.pth\ LSUN-Cat: lsun_cat.pth\ LSUN-Horse: lsun_horse.pth
Training setups:
| Dataset | Backbone | epochs | batch-size | mask-ratio |
|---|---|---|---|---|
| LSUN Bedroom | ViT-L-8 | 150 | 1024 | 0.75 |
| LSUN Cat | ViT-L-8 | 200 | 1024 | 0.75 |
| LSUN Horse | ViT-L-8 | 200 | 1024 | 0.75 |
| FFHQ-256 | ViT-L-8 | 400 | 1024 | 0.75 |
Run
- Download the datasets:\
bash datasets/download_datasets.sh - Download the MAE checkpoint:\
bash checkpoints/mae/download_checkpoint.sh <checkpoint_name> - Check paths in
experiments/<dataset_name>/mae.json - Run:
bash scripts/mae/train_interpreter.sh <dataset_name>
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse\ Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21, celeba_19, ade_bedroom_30
SwAV
Pretrained SwAVs
We pretrain SwAV models using the official implementation on the LSUN and FFHQ-256 datasets:
| LSUN-Bedroom | FFHQ-256 | LSUN-Cat | LSUN-Horse |
|---|---|---|---|
| SwAV | SwAV | SwAV | SwAV |
| SwAVw2 | SwAVw2 | SwAVw2 | SwAVw2 |
Training setups:
| Dataset | Backbone | epochs | batch-size | multi-crop | num-prototypes |
|---|---|---|---|---|---|
| LSUN | RN50 | 200 | 1792 | 2x256 + 6x108 | 1000 |
| FFHQ-256 | RN50 | 400 | 2048 | 2x224 + 6x96 | 200 |
| LSUN | RN50w2 | 200 | 1920 | 2x256 + 4x108 | 1000 |
| FFHQ-256 | RN50w2 | 400 | 2048 | 2x224 + 4x96 | 200 |
Run
- Download the datasets:\
bash datasets/download_datasets.sh - Download the SwAV checkpoint:\
bash checkpoints/{swav|swav_w2}/download_checkpoint.sh <checkpoint_name> - Check paths in
experiments/<dataset_name>/{swav|swav_w2}.json - Run:
bash scripts/{swav|swav_w2}/train_interpreter.sh <dataset_name>
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse\ Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21, celeba_19, ade_bedroom_30
DatasetGAN
Opposed to the official implementation, more recent StyleGAN2(-ADA) models are used.
Synthetic datasets
To download GAN-produced synthetic datasets (50000 samples):
bash synthetic-datasets/gan/download_synthetic_dataset.sh <dataset_name>
Run
Since we almost fully adopt the official implementation, we don't provide our reimplementation here. However, one can still reproduce our results:
- Download the synthetic dataset:\
bash synthetic-datasets/gan/download_synthetic_dataset.sh <dataset_name> - Change paths in
experiments/<dataset_name>/datasetDDPM.json - Change paths and run:
bash scripts/datasetDDPM/train_deeplab.sh <dataset_name>
Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21
Results
- Performance in terms of mean IoU:
| Method | Bedroom-28 | FFHQ-34 | Cat-15 | Horse-21 | CelebA-19 | ADE-Bedroom-30 |
|---|---|---|---|---|---|---|
| ALAE | 20.0 ± 1.0 | 48.1 ± 1.3 | -- | -- | 49.7 ± 0.7 | 15.0 ± 0.5 |
| VDVAE | -- | 57.3 ± 1.1 | -- | -- | 54.1 ± 1.0 | -- |
| GAN Inversion | 13.9 ± 0.6 | 51.7 ± 0.8 | 21.4 ± 1.7 | 17.7 ± 0.4 | 51.5 ± 2.3 | 11.1 ± 0.2 |
| GAN Encoder | 22.4 ± 1.6 | 53.9 ± 1.3 | 32.0 ± 1.8 | 26.7 ± 0.7 | 53.9 ± 0.8 | 15.7 ± 0.3 |
| SwAV | 41.0 ± 2.3 | 54.7 ± 1.4 | 44.1 ± 2.1 | 51.7 ± 0.5 | 53.2 ± 1.0 | 30.3 ± 1.5 |
| SwAVw2 | 42.4 ± 1.7 | 56.9 ± 1.3 | 45.1 ± 2.1 | 54.0 ± 0.9 | 52.4 ± 1.3 | 30.6 ± 1.0 |
| MAE | 45.0 ± 2.0 | 58.8 ± 1.1 | 52.4 ± 2.3 | 63.4 ± 1.4 | 57.8 ± 0.4 | 31.7 ± 1.8 |
| DatasetGAN | 31.3 ± 2.7 | 57.0 ± 1.0 | 36.5 ± 2.3 | 45.4 ± 1.4 | -- | -- |
| DatasetDDPM | 47.9 ± 2.9 | 56.0 ± 0.9 | 47.6 ± 1.5 | 60.8 ± 1.0 | -- | -- |
| DDPM | 49.4 ± 1.9 | 59.1 ± 1.4 | 53.7 ± 3.3 | 65.0 ± 0.8 | 59.9 ± 1.0 | 34.6 ± 1.7 |
- Examples of segmentation masks predicted by the DDPM-based method:

Cite
@misc{baranchuk2021labelefficient,
title={Label-Efficient Semantic Segmentation with Diffusion Models},
author={Dmitry Baranchuk and Ivan Rubachev and Andrey Voynov and Valentin Khrulkov and Artem Babenko},
year={2021},
eprint={2112.03126},
archivePrefix={arXiv},
primaryClass={cs.CV}
}