Multi-Modality Guided Transformer (ECCV 2022)
This official repository implements MMT (Unbiased Multi-Modality Guidance for Image Inpainting) using PyTorch 1.8.0
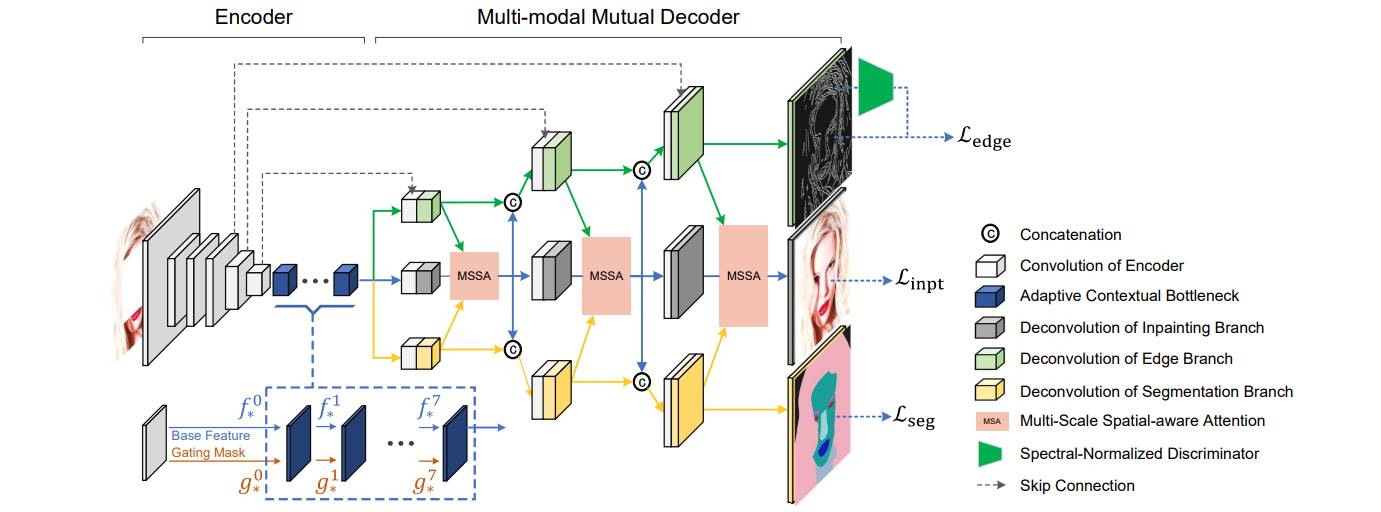
Paper | Pre-trained Models | Demo
:wrench: Prerequisites
- Python 3.8.8
- Pytorch 1.8
- NVIDIA GPU + CUDA cuDNN
pip install -r requirements.txt
:balloon: Prepare dataset
It assumes all datasets placed in the data_root "../training_data/" .
1. RGB images
| dataset | DATANAME | number of semantic categories | source |
|---|---|---|---|
| CelebA-HQ | CelebAMask-HQ | 15 | https://github.com/switchablenorms/CelebAMask-HQ |
| Outdoor Scenes | OST | 9 | http://mmlab.ie.cuhk.edu.hk/projects/SFTGAN/ |
| CityScapes | CityScape | 20 | https://www.cityscapes-dataset.com |
Downloading RGB image datasets from above links. Then split to train/test set, then place them to f"../training_data/{DATANAME}/img/train/" or f"../training_data/{DATANAME}/img/test/" .
2. Edge maps
Run python utils/generate_canny_edge.py to pre-generate edge maps for corresponding RGB images. Placing them to f"../training_data/{DATANAME}/edge/train/".
Optional:
In code dataset.py, note off the skimage-canny comments line for generate corresponding edge maps while sample RGB data.
3. Segmentation maps
Three datasets contain own hand-crafted segmentation maps. Except CelebA-HQ that we merge all left and right parsing, e.g., left eye and right eye => eyes, we remain the original setting of segmentation of OST and CityScapes.
Generation script for splicing parsing of CelebA-HQ is utils/generate_face_parsing.py and splicing parsing of CityScapes is utils/generate_cityscape_parsing.py. OST already provides spliced parsing PNG images. Notably, all segmentation maps of three datasets are converted to one-hot format that save as *.npy for training.
If this is still holding you back, please feel free to download pre-generated segmentation maps on google drive (named anno_*.tar.gz).
Similar to RGB images and edges, place segmentation maps to f"../training_data/{DATANAME}/anno/train/" .
4. About dataset split
- OST includes 9900 training images and 300 testing images.
- In CityScapes dataset, 2975 images from the training set and 1525 images from the test set for training, and test on the 500 images from the validation set.
- CelebA-HQ includes 30000 images, use the first 29000 images for training, and use the last 1000 images for testing.
:arrow_forward: Train and Inference
Train
To perform training, use
python train.pyThere are several arguments that can be used, which are
--dataset +str #DATANAME, one of CelebAMask-HQ, OST, CityScape
--data_root +str #DATASETS DIR
--num_iters +int #TRAINING ITERATION, no need changing
--batch_size +int #scale memory for your device
--gpu_id +str #which gpu to use
--auxiliary_type +str #NETWORK TYPE, no need changing
--local_canny_edge +str #EDGE LABEL, switch generate method of edge labelTest
| Pretrained Weights |
|---|
| CelebA-HQ |
| OST |
| Cityscape |
To quick test, use
python test.py --ckpt checkpoint/MMT-CelebAHQ.pthThere are several arguments that can be used, which are
--dataset +str #DATANAME, one of CelebAMask-HQ, OST, CityScape
--data_root +str #DATASETS DIR
--mask_root +str #local mask files
--save_root +str #inference results dir
--mask_mode +str #MASK TYPE
--ckpt +str #pretrain weights location
--verbose #output predicted segmentation and edgeTips:
- Masks should be binarized when change scale.
PIL.Image.open(mask_path).convert('1').resize((h,w)) - We retrained the model on another device, so that the results may slightly differ from the reported ones.
:hourglass_flowing_sand: To Do
- [x] Release training code
- [x] Release testing code
- [x] Release pre-trained model of CelebA-HQ
- [ ] Release pre-trained models of OST, Cityscapes
- [ ] Release a web demo
:book: Citations
Please cite this project in your publications if it helps your research. The following is a BibTeX reference.
TBA:bulb: Acknowledgments
We thank the authors of RFR-Net and STTN for sharing their codes.