DoraemonGPT : Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent)
: Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent)
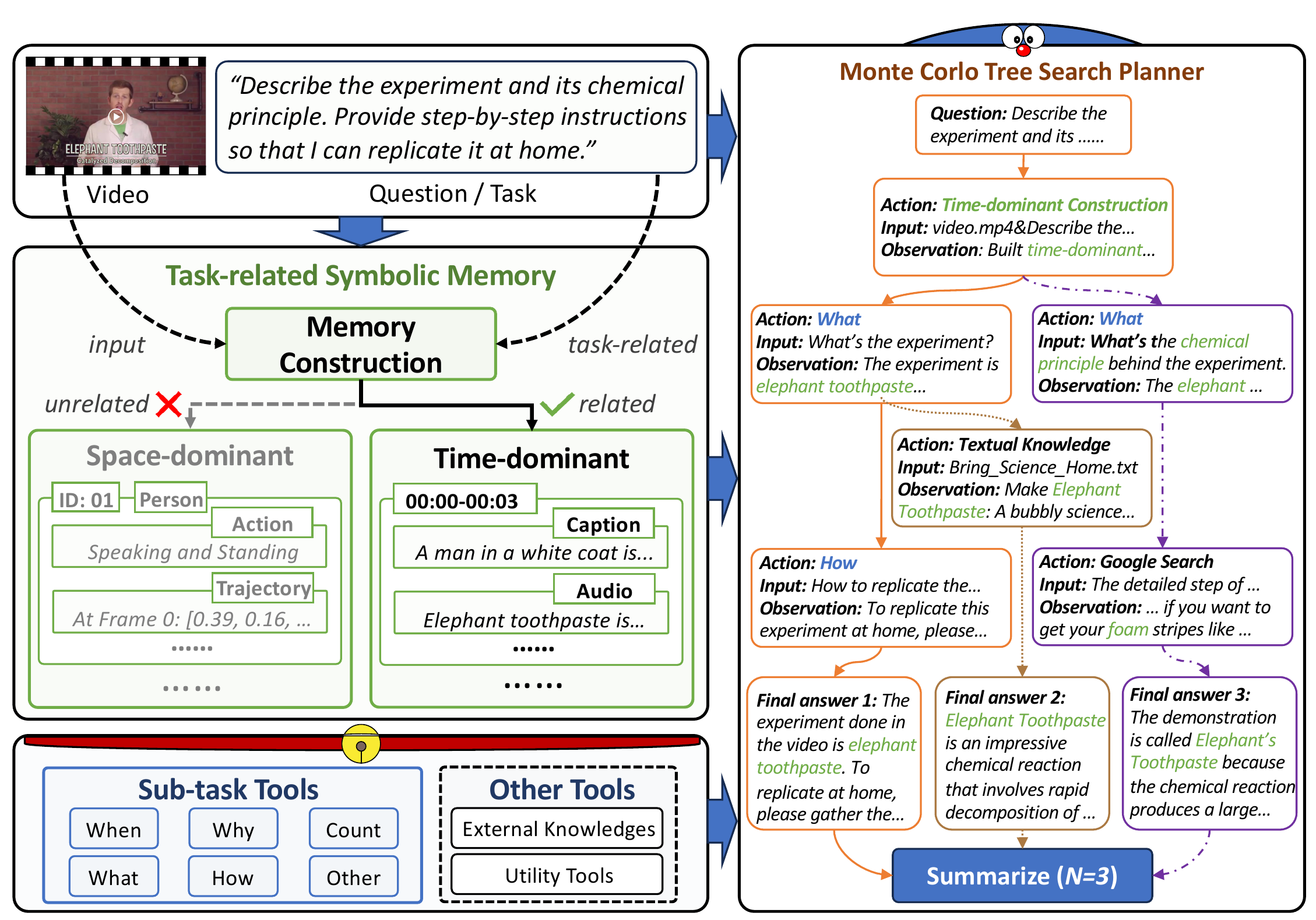 Overview. Given a video with a question/task, DoraemonGPT first extracts a Task-related Symbolic Memory, which has two types of memory for selection: space-dominant memory based on instances and time-dominant memory based on time frames/clips. The memory can be queried by sub-task tools, which are driven by LLMs with different prompts and generate symbolic language (i.e., SQL sentences) to do different reasoning. Also, other tools for querying external knowledge or utility tools are supported. For planning, DoraemonGPT employs the MCTS Planner to decompose the question into an action sequence by exploring multiple feasible N solutions, which can be further summarized into an informative answer.
Overview. Given a video with a question/task, DoraemonGPT first extracts a Task-related Symbolic Memory, which has two types of memory for selection: space-dominant memory based on instances and time-dominant memory based on time frames/clips. The memory can be queried by sub-task tools, which are driven by LLMs with different prompts and generate symbolic language (i.e., SQL sentences) to do different reasoning. Also, other tools for querying external knowledge or utility tools are supported. For planning, DoraemonGPT employs the MCTS Planner to decompose the question into an action sequence by exploring multiple feasible N solutions, which can be further summarized into an informative answer.
Setup and Configuration 🛠️
- Python Version: Python 3.9 or newer installed on your system.
- API Keys: Obtain API keys from one or more of the following services:
- OpenAI (for access to models like GPT-3.5)
- Google Cloud (for access to models like OCR)
- Google Search (for access to search online)
- Python Dependencies: Install all necessary Python libraries as specified in the
requirements.txtfile. You can install these dependencies using the following command:pip install -r requirements.txt - Other Model Choice: You have the option to use models from Hugging Face's Transformers library. Ensure you have the necessary credentials to use and download the model.
Installation Steps
- Clone the repository 📦:
git clone https://github.com/z-x-yang/DoraemonGPT.git - Opt for a virtual environment 🧹 and install the dependencies 🧑🍳:
pip install -r requirements.txt -
Set up your API key 🗝️:
-
Fill in config/inference/inference.yaml with your keys:
openai: GPT_API_KEY: ["put your openai key here", ...] google_cloud: CLOUD_VISION_API_KEY: [...] QUOTA_PROJECT_ID: [...]
-
-
Download the checkpoints and bulid related project🧩:
Thanks for the authors of these open source projects below for providing valuable pre-training models with outstanding performance🤝. When utilizing these models, users must strictly adhere to the authors' licensing agreements and properly cite the sources in published works.
-
download the pretrained model for action recognition
mkdir checkpoints cd ./checkpoints #download the pretrained model for action recognition wget https://pjlab-gvm-data.oss-cn-shanghai.aliyuncs.com/uniformerv2/k400/k400_k710_uniformerv2_b16_8x224.pyth -
download the pretrained model for yolo-tracking
#download the pretrained model for object detection and tracking wget https://objects.githubusercontent.com/github-production-release-asset-2e65be/521807533/0c7608ab-094c-4c63-8c0c-3e7623db6114?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20240612%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20240612T083947Z&X-Amz-Expires=300&X-Amz-Signature=7b6688c64e3d3f1eb54a0eca30ca99e140bed9f886d4c8a084bec389046ecda8&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=521807533&response-content-disposition=attachment%3B%20filename%3Dyolov8n-seg.pt&response-content-type=application%2Foctet-stream wget https://objects.githubusercontent.com/github-production-release-asset-2e65be/521807533/67360104-677c-457e-95a6-856f07ba3f2e?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20240612%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20240612T083803Z&X-Amz-Expires=300&X-Amz-Signature=8bd5d0f9ef518ee1a84783203b2d0a6c285a703dace053ae30596c68f2428599&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=521807533&response-content-disposition=attachment%3B%20filename%3Dyolov8n.pt&response-content-type=application%2Foctet-stream - download the pretrained model for dense captioning
mkdir ./blip cd ./blip # dowlond the chekpoints from below [[Hugging Face](https://huggingface.co/Salesforce/blip-image-captioning-large/tree/main)] cd .. - download the pretrained model for inpainting
#download the pretrained model for inpainting mkdir ./E2FGVI cd ./E2FGVI # dowlond the chekpoints from below [[Google Drive](https://drive.google.com/file/d/1tNJMTJ2gmWdIXJoHVi5-H504uImUiJW9/view?usp=sharing)] [[Baidu Disk](https://pan.baidu.com/s/1qXAErbilY_n_Fh9KB8UF7w?pwd=lsjw)] cd .. -
download the pretrained model for rvos
#download the pretrained model for rvos mkdir AOT cd ./AOT # dowlond the chekpoints from below [[Google Drive](https://drive.google.com/file/d/1QoChMkTVxdYZ_eBlZhK2acq9KMQZccPJ/view)] cd .. mkdir GroundedSAM cd ./GroundedSAM wget https://objects.githubusercontent.com/github-production-release-asset-2e65be/611591640/c4c55fde-97e5-47d9-a2c5-b169832a2fa9?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20240623%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20240623T053405Z&X-Amz-Expires=300&X-Amz-Signature=369fd1d480eb018f7b3a31e960835ae77ae5bb9b1d0dcc5415751811daf4e325&X-Amz-SignedHeaders=host&actor_id=97865789&key_id=0&repo_id=611591640&response-content-disposition=attachment%3B%20filename%3Dgroundingdino_swinb_cogcoor.pth&response-content-type=application%2Foctet-stream # dowlond the chekpoints from below [[Github](https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt)] cd ../..
-
QuickStart 🚀
- Fill in config/demo.yaml with your video and question:
# run cd .. python ./scripts/demo_test.py --config config/demo_2.yaml
News and Todo🗓️
- [x] Release Code for Demo
- [ ] Release Code for Benchmarks
- [ ] Release Code with Video-LLaVA
Overview 📜
Thanks to the authors of these open source projects for providing excellent projects.
Memory Construction
- Time-dominant Memory ⏱️
- Audio content
- Whisper
- Captioning
- BLIP/ BLIP2/ InstructBLIP
- Optical content
- Google cloud
- Space-dominant Memory 🌐
- Category & Trajectory & Segmentation
- BOXMOT(yolo-tracking)+yolov8-seg
- GroundedSAM+Deaot
- Appearance
- BLIP/ BLIP2/ InstructBLIP
- Action Recognition
- InternVideo
Tool Usage
- GoogleSearch
- langchain - google
- Google Search | 🦜️🔗 Langchain
- VideoInpainting
- E2FGVI
- [MCG-NKU/E2FGVI: Official code for "Towards An End-to-End Framework for Flow-Guided Video Inpainting" (CVPR2022) (github.com)](https://github.com/MCG-NKU/E2FGVI "MCG-NKU/E2FGVI: Official code for \"Towards An End-to-End Framework for Flow-Guided Video Inpainting\" (CVPR2022) (github.com)")
Citations
Please consider citing the related paper(s) in your publications if it helps your research.
@inproceedings{yang2024doraemongpt,
title={Doraemongpt: Toward understanding dynamic scenes with large language models (exemplified as a video agent)},
author={Yang, Zongxin and Chen, Guikun and Li, Xiaodi and Wang, Wenguan and Yang, Yi},
booktitle={Forty-first International Conference on Machine Learning}
}License 🏷️
This project is all yours under the MIT License.