Stargazer
This is a python port of the R stargazer package that can be found on CRAN. I was disappointed that there wasn't equivalent functionality in any python packages I was aware of so I'm re-implementing it here.
There is an experimental function in the statsmodels.regression.linear_model.OLSResults.summary2 that can report single regression model results in HTML/CSV/LaTeX/etc, but it still didn't quite fulfill what I was looking for.
The python package is object oriented now with chained commands to make changes to the rendering parameters, which is hopefully more pythonic and the user doesn't have to put a bunch of arguments in a single function.
Installation
You can install this package through PyPi with pip install stargazer or just clone the repo and take the stargazer.py file since it's the only one in the package.
Dependencies
It depends on statsmodels, which in turn depends on several other libraries like pandas, numpy, etc
Editing Features
This library implements many of the customization features found in the original package. Examples of most can be found in the examples jupyter notebook and a full list of the methods/features is here below:
title: custom titleshow_header: display or hide model header datashow_model_numbers: display or hide model numberscustom_columns: custom model names and model groupingssignificance_levels: change statistical significance thresholdssignificant_digits: change number of significant digitsshow_confidence_intervals: display confidence intervals instead of variancedependent_variable_name: rename dependent variablerename_covariates: rename covariatescovariate_order: reorder covariatesreset_covariate_order: reset covariate order to original orderingshow_degrees_of_freedom: display or hide degrees of freedomcustom_note_label: label notes section at bottom of tableadd_custom_notes: add custom notes to section at bottom of the tableadd_line: add a custom line to the tableappend_notes: display or hide statistical significance thresholds
These features are agnostic of the rendering type and will be applied whether the user outputs in HTML, LaTeX, etc
Example
Here is an examples of how to quickly get started with the library. More examples can be found in the examples.ipynb file in the github repo. The examples all use the scikit-learn diabetes dataset, but it is not a dependency for the package.
OLS Models Preparation
import pandas as pd
from sklearn import datasets
import statsmodels.api as sm
from stargazer.stargazer import Stargazer
diabetes = datasets.load_diabetes()
df = pd.DataFrame(diabetes.data)
df.columns = ['Age', 'Sex', 'BMI', 'ABP', 'S1', 'S2', 'S3', 'S4', 'S5', 'S6']
df['target'] = diabetes.target
est = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[0:4]])).fit()
est2 = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[0:6]])).fit()
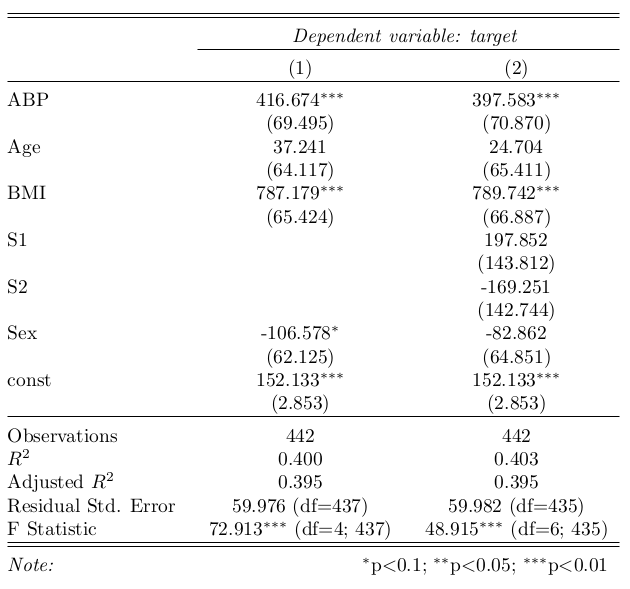
stargazer = Stargazer([est, est2])HTML Example
stargazer.render_html()| Dependent variable: target | ||
| (1) | (2) | |
| ABP | 416.674*** | 397.583*** |
| (69.495) | (70.870) | |
| Age | 37.241 | 24.704 |
| (64.117) | (65.411) | |
| BMI | 787.179*** | 789.742*** |
| (65.424) | (66.887) | |
| S1 | 197.852 | |
| (143.812) | ||
| S2 | -169.251 | |
| (142.744) | ||
| Sex | -106.578* | -82.862 |
| (62.125) | (64.851) | |
| const | 152.133*** | 152.133*** |
| (2.853) | (2.853) | |
| Observations | 442 | 442 |
| R2 | 0.400 | 0.403 |
| Adjusted R2 | 0.395 | 0.395 |
| Residual Std. Error | 59.976 (df=437) | 59.982 (df=435) |
| F Statistic | 72.913*** (df=4; 437) | 48.915*** (df=6; 435) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
LaTeX Example
stargazer.render_latex()