stemflow :bird:
![]()
A Python Package for Adaptive Spatio-Temporal Exploratory Model (AdaSTEM)






![]()

Documentation :book:
Installation :wrench:
pip install stemflowTo install the latest beta version from github:
pip install stemflow@git+https://github.com/chenyangkang/stemflow.gitOr using conda:
conda install -c conda-forge stemflowBrief introduction :information_source:
stemflow is a toolkit for Adaptive Spatio-Temporal Exploratory Model (AdaSTEM [1, 2]) in Python. Typical usage is daily abundance estimation using eBird citizen science data (survey data).
stemflow adopts "split-apply-combine" philosophy. It
- Splits input data using Quadtree or Sphere Quadtree.
- Trains each spatiotemporal split (called stixel) separately.
- Aggregates the ensemble to make the prediction.
The framework leverages the "adjacency" information of surroundings in space and time to model/predict the values of target spatiotemporal points. This framework ameliorates the long-distance/long-range prediction problem [3], and has a good spatiotemporal smoothing effect.
For more information, please see an introduction to stemflow and learning curve analysis
Model and data :slot_machine:
Main functionality of stemflow |
Supported indexing | Supported tasks |
|---|---|---|
| :white_check_mark: Spatiotemporal modeling & prediction |
:white_check_mark: User-defined 2D spatial indexing (CRS) |
:white_check_mark: Binary classification task |
| :white_check_mark: Calculate overall feature importances |
:white_check_mark: 3D spherical indexing |
:white_check_mark: Regression task |
| :white_check_mark: Plot spatiotemporal dynamics |
:white_check_mark: User-defined temporal indexing |
:white_check_mark: Hurdle task (two step regression – classify then regress the non-zero part) |
| :white_check_mark: Spatial-only modeling |
||
| For details see AdaSTEM Demo | For details and tips see Tips for spatiotemporal indexing | For details and tips see Tips for different tasks |
| Supported data types | Supported base models |
|---|---|
| :white_check_mark: Both continuous and categorical features (prefer one-hot encoding) |
:white_check_mark: sklearn style BaseEstimator classes (you can make your own base model), for example here |
| :white_check_mark: Both static (e.g., yearly mean temperature) and dynamic features (e.g., daily temperature) |
:white_check_mark: sklearn style Maxent model. Example here. |
| For details and tips see Tips for data types | For details see Base model choices |
Usage :star:
Use Hurdle model as the base model of AdaSTEMRegressor:
from stemflow.model.AdaSTEM import AdaSTEM, AdaSTEMClassifier, AdaSTEMRegressor
from stemflow.model.Hurdle import Hurdle
from xgboost import XGBClassifier, XGBRegressor
## "hurdle in Ada"
model = AdaSTEMRegressor(
base_model=Hurdle(
classifier=XGBClassifier(tree_method='hist',random_state=42, verbosity = 0, n_jobs=1),
regressor=XGBRegressor(tree_method='hist',random_state=42, verbosity = 0, n_jobs=1)
), # hurdel model for zero-inflated problem (e.g., count)
save_gridding_plot = True,
ensemble_fold=50, # data are modeled 50 times, each time with jitter and rotation in Quadtree algo
min_ensemble_required=30, # Only points covered by > 30 ensembles will be predicted
grid_len_upper_threshold=25, # force splitting if the grid length exceeds 25
grid_len_lower_threshold=5, # stop splitting if the grid length fall short 5
temporal_start=1, # The next 4 params define the temporal sliding window
temporal_end=366,
temporal_step=20, # The window takes steps of 20 DOY (see AdaSTEM demo for details)
temporal_bin_interval=50, # Each window will contain data of 50 DOY
points_lower_threshold=50, # Only stixels with more than 50 samples are trained and used for prediction
Spatio1='longitude', # The next three params define the name of
Spatio2='latitude', # spatial coordinates shown in the dataframe
Temporal1='DOY',
use_temporal_to_train=True, # In each stixel, whether 'DOY' should be a predictor
n_jobs=1,
random_state=42
)Fitting and prediction methods follow the style of sklearn BaseEstimator class:
## fit
model = model.fit(X_train.reset_index(drop=True), y_train)
## predict
pred = model.predict(X_test)
pred = np.where(pred<0, 0, pred)
eval_metrics = AdaSTEM.eval_STEM_res('hurdle',y_test, pred_mean)
print(eval_metrics)Where the pred is the mean of the predicted values across ensembles.
See AdaSTEM demo for further functionality.
See Optimizing stixel size for why and how you should tune the important gridding parameters.
Plot QuadTree ensembles :evergreen_tree:
model.gridding_plot
# Here, the model is a AdaSTEM class, not a hurdle class
Here, each color shows an ensemble generated during model fitting. In each of the 10 ensembles, regions (in terms of space and time) with more training samples were gridded into finer resolution, while the sparse one remained coarse. Prediction results were aggregated across the ensembles (that is, in this example, data were modeled 10 times).
If you use SphereAdaSTEM module, the gridding plot is a plotly generated interactive object by default:
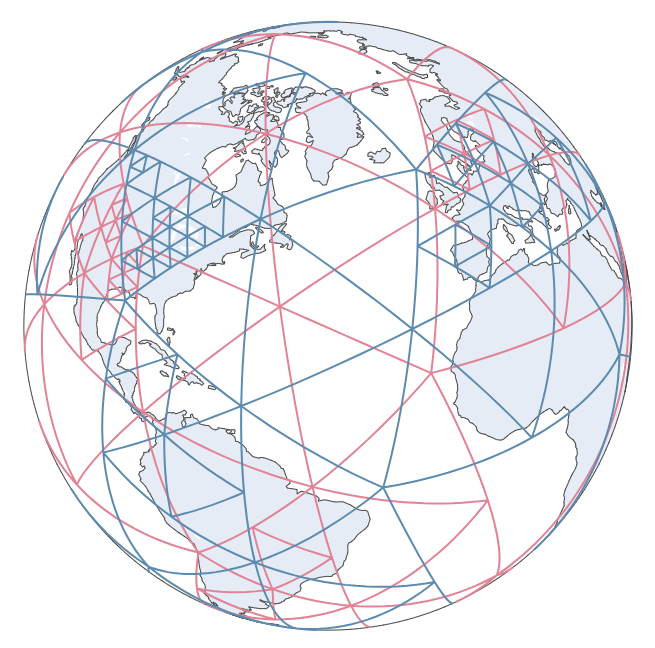
See SphereAdaSTEM demo and Interactive spherical gridding plot.
Example of visualization :world_map:
Daily Abundance Map of Barn Swallow

See section AdaSTEM demo for how to generate this GIF.
Citation
Chen et al., (2024). stemflow: A Python Package for Adaptive Spatio-Temporal Exploratory Model. Journal of Open Source Software, 9(94), 6158, https://doi.org/10.21105/joss.06158
@article{Chen2024,
doi = {10.21105/joss.06158},
url = {https://doi.org/10.21105/joss.06158},
year = {2024},
publisher = {The Open Journal},
volume = {9},
number = {94},
pages = {6158},
author = {Yangkang Chen and Zhongru Gu and Xiangjiang Zhan},
title = {stemflow: A Python Package for Adaptive Spatio-Temporal Exploratory Model},
journal = {Journal of Open Source Software}
}Contribute to stemflow :purple_heart:
We welcome pull requests. Contributors should follow contributor guidelines.
Application-level cooperation is also welcomed. We recognized that stemflow may consume large computational resources especially as data volume boosts in the future. We always welcome research collaboration of all kinds.
References: