A Simple Soc with DMAC and Ethernet controller
Branch
- matser
A simple Soc only with uart- ise dir xc3s500e-4vq100@50MHz
- v6
A Soc with DMAC and Ethmac(gmii)- ise dir xc6vlx75t-1ff484@208MHz
- vivado dir xc7k325tffg900-2@333MHz
- sgmii
A Soc with DMAC and Ethmac(sgmii)- vivado dir xc7k030fbg676-2@333MHz
Introduction
This is a repository for riscv learning. I want to implement the tcp protocol in some FPGAs without embedded ARM core, but it is too complicated to implement by verilog. So I chose a processor soft core to accomplish what I want.
Theoretically, it can reach a speed of 100Mbps, and there is no problem for some common data collection and transmission applications.
Features:
- Picrorv32 RISCV core
- 128KB RAM
- ethernet controller
- DMA controller
- FIFO UART
- xc6vlx75t-1ff484 208MHz
- xc7k325tffg900-2 333MHz

How To Compile
download riscv-gnu-toolchain
-
For Ubuntu
-
-marchwill generate wrong ISA mismatch your ISA combinations. For example, if you want to generate [im] instructions, you should configure toolchain with rv32im rather than rv32imc. This problem happens only on Linux. I don't know why.
# Ubuntu packages needed:
sudo apt-get install autoconf automake autotools-dev curl libmpc-dev \
libmpfr-dev libgmp-dev gawk build-essential bison flex texinfo \
gperf libtool patchutils bc zlib1g-dev git libexpat1-dev
sudo mkdir /opt/riscv32imc
sudo chown $USER /opt/riscv32imc
git clone https://github.com/riscv/riscv-gnu-toolchain riscv-gnu-toolchain-rv32imc
cd riscv-gnu-toolchain-rv32imc
git checkout 411d134 # (just for a stable version, you can change it to a updated one)
git submodule update --init --recursive
mkdir build; cd build
../configure --with-arch=rv32imc --prefix=/opt/riscv32imc
make -j$(nproc)- For Windows
At first I only found 64-bit libraries. Suddenly, I realized that 64 bit library can compile 32 bit program, so we can do all of these compile on Windows. The prebuilt library you can download at this page. Prebuilt Windows Toolchain for RISC-V
Compile Software
# Windows os / cygwin
cd firmware
# generate firmware.elf and some .hex for simulation
make firmwareCompile Hardware
# Windows os / cygwin
# at root directory
# Compile FPGA bit stream
make hw
# write firmware.elf to Block RAMs
# and program FPGA
make hw_progSimulation
# use iverilog for simulation
# before this you shold compile firmware.elf and generate hex files
make hw_simDMA controllor
I implemented a simple DMA controller with a ring buffer. When the C program pre-allocates several memory blocks for network reception, it will write start address of the memory to the address register of the DMAC. Once the network controller receives a frame and the ring buffer is not full, DMA will occupy the memory bus in the next processor idle cycle, and write data to the memory. DMAC will release the bus after the write operation is completed.
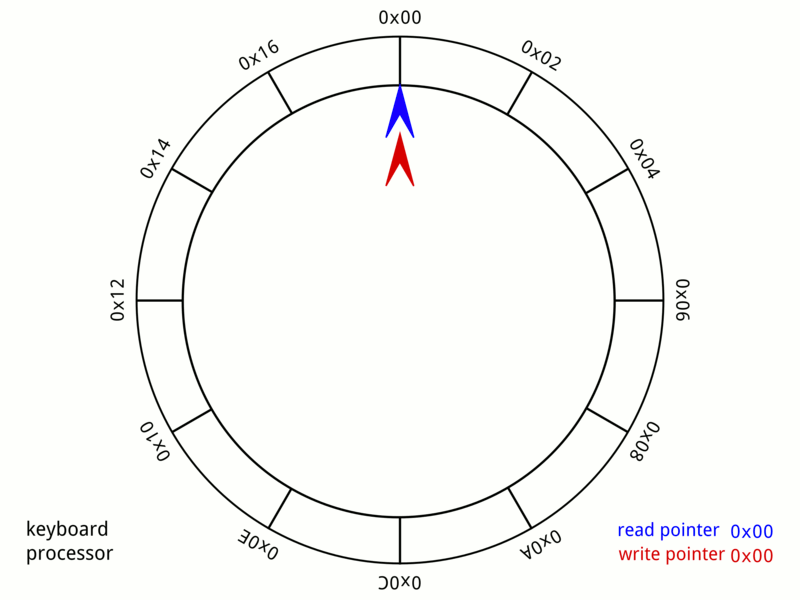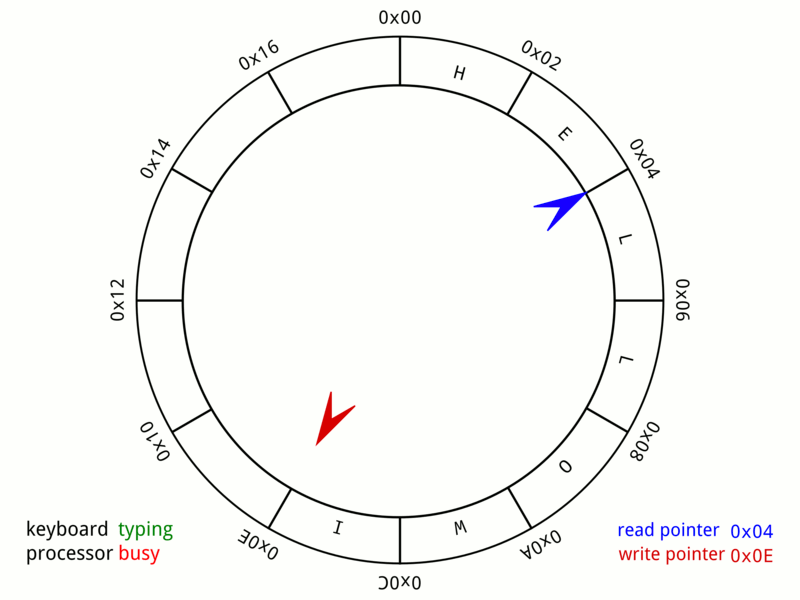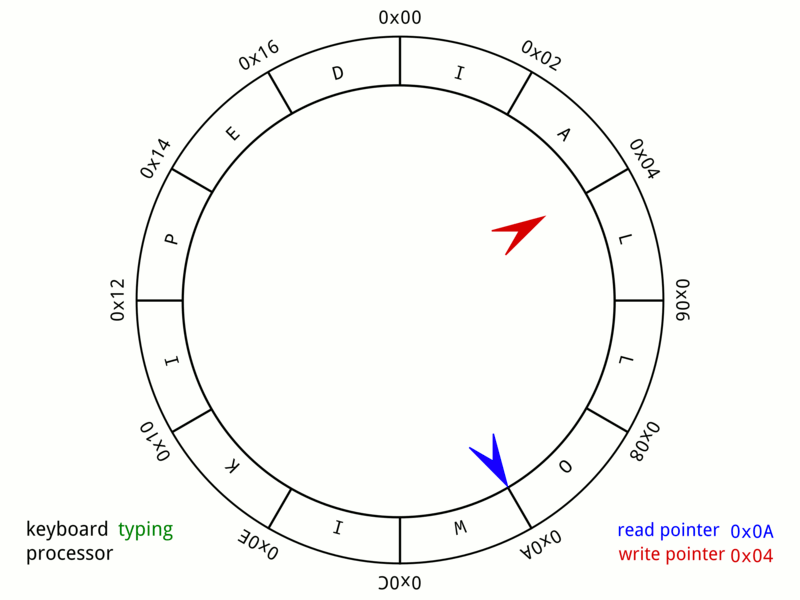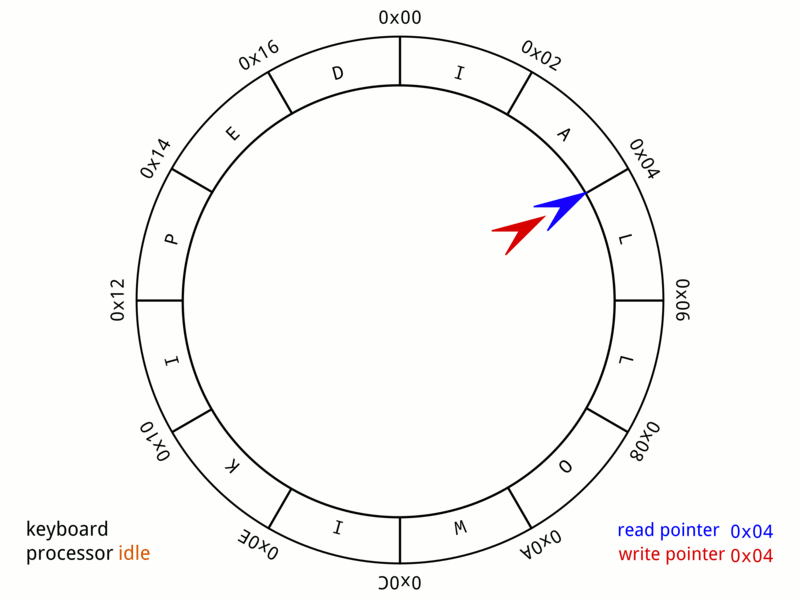
In order to reduce the impact of the DMA occupying the bus on the execution of processor instructions. The memory space is divided into two parts, instruction space and heap space. The dynamically allocated memory is only allocated on the heap space, so DMA only occupies the heap memory bus, which reduces time processor waiting.
Considering the overhead of a series of stack pushing and poping operations when processor interrupts, the DMA generates an interrupt every time it receives an Ethernet packet, which causes the processor to be overburdened. So the DMA interrupt uses a polling method. Every 1ms check if any data has been written to the memory and wait for processing. If there is, an interrupt will be generated; if not, it will not be generated.
After the processor processes a frame of data, it frees that piece of memory and mallocs a new one. Then processor writes the first address to the address register of the ring buffer, and set the status bit of the corresponding block of the ring buffre to zero. so that the DMAC can wait to start a new transmission.
The DMA sending part also uses a ring buffer. But for programming simplicity, I only enabled one sending block. As long as the first address and length of the transmission data are written, one transmission can be completed.
The first address of the data block for reception must be aligned with 4 bytes, but the data block will be sent does not need to be aligned with 4 bytes.
ethernet controllor
There are two 4KB FIFOs inside, which convert gmii interface to AXI Stream interface for processor and DMA access.
FIFO UART
The original version used a UART without FIFO. The baud rate is much slower than processor. If you the last sent have not finished when writing a new ascii code, processor will be blocked until the new byte has been written successfully.
Using FIFO UART can reduce the idle time of the processor and improve efficiency.
Utilization
| ISE | ||
|---|---|---|
| Number of DSP48E1s | 4 out of 288 | 1% |
| Number of RAMB36E1s | 36 out of 156 | 23% |
| Number of Slice Registers | 4389 out of 93,120 | 4% |
TODO
- interrupt controller
- ...