Minecraft-Reinforcement-Learning
We here compare Deep Recurrent Q-Learning and Deep Q-Learning on two simple missions in a Partially Observable Markov Decision Process (POMDP) based on Minecraft environment. We use gym-minecraft which allows the use of the MalmoProject with an OpenAI like API.
Our work is in the notebook DRQN_vs_DQN_minecraft.ipynb.
Our paper can be found here.
Work realised in collaboration with :
Prerequisites
- Python 3.6
- Jupyter
- Tensorflow
Installation
- You need to install Malmö
- You can then install gym-minecraft
- You can find in the folder "envs" :
- The slightly modified version of gym-minecraft main code we used named
minecraft.py. Put it inyour_pip_folder/site-packages/gym_minecraft-0.0.2-py3.6.egg/gym-minecraft/envs/
- The slightly modified version of gym-minecraft main code we used named
- The missions we used. Put them in
your_pip_folder/site-packages/gym_minecraft-0.0.2-py3.6.egg/gym-minecraft/assets/
Models
You can choose between 3 models :
- Simple DQN : Convolutional Neural Network with the current frame
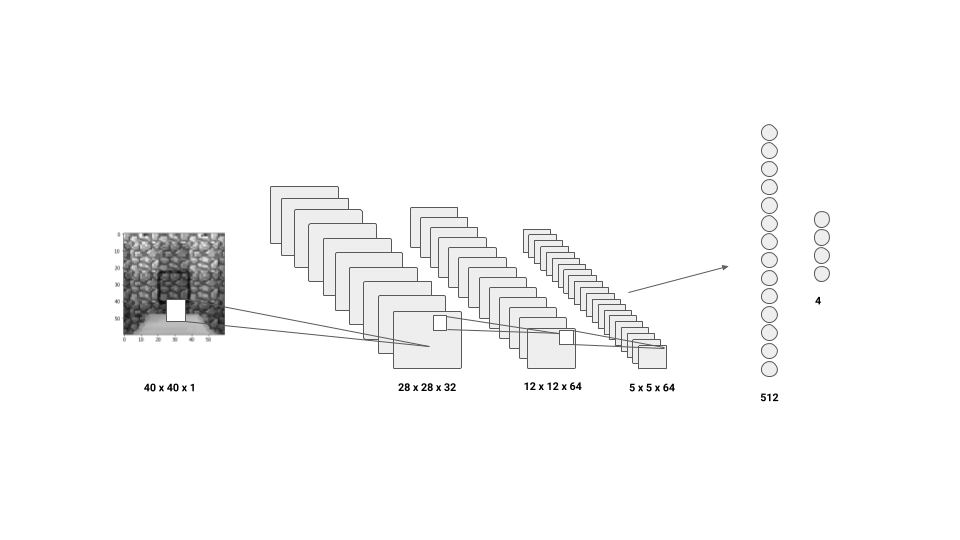
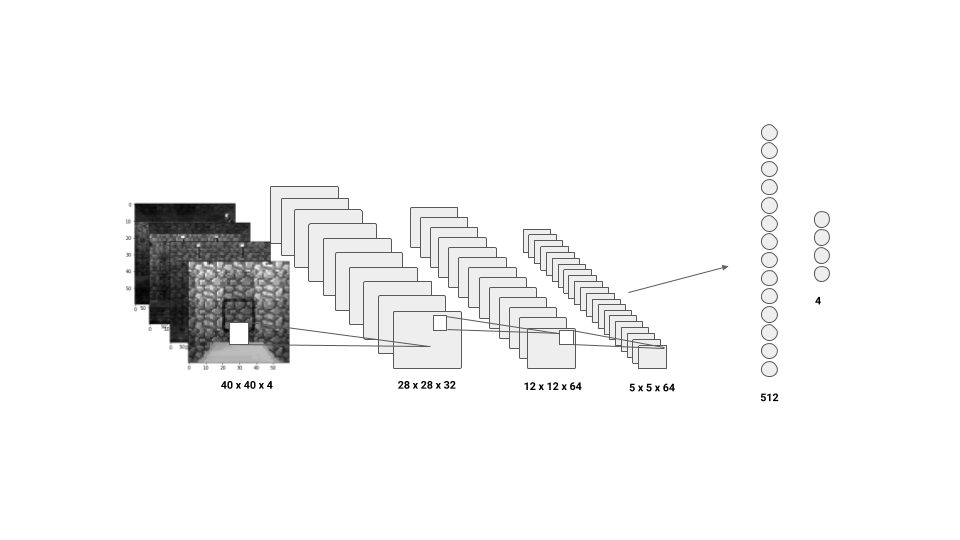
- DQN : Convolutional Neural Network with the last 4 frames
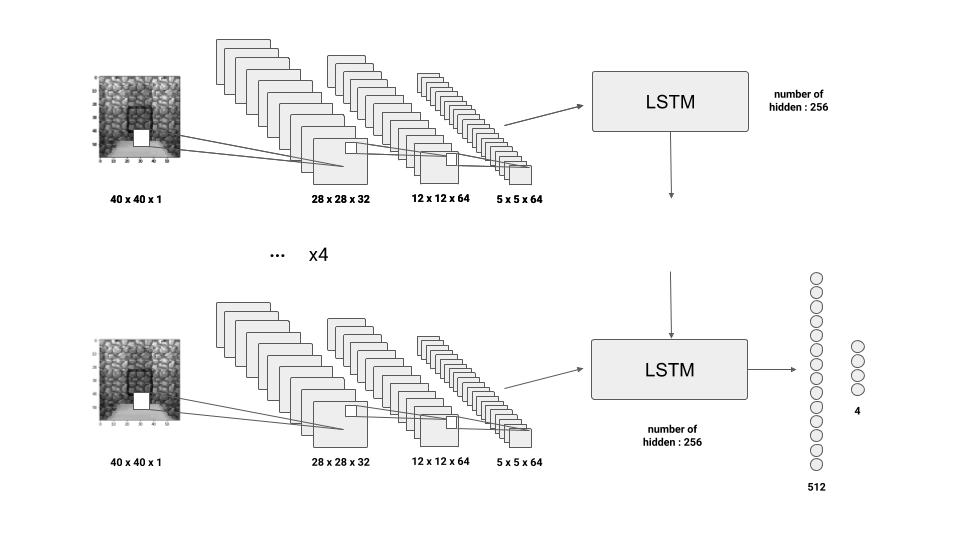
- DRQN : Convolutional Neural Network + LSTM layer
DQN settings
- Implementation of Double Q Learning
- ε-greedy exploration
- Experience replay iplementation
Note
Unlike Deepmind’s implementations of DQN for Atari games, Minecraft has the constraint that the game isn’t in pause during two actions ordered by the agent. Accordingly the agent and the network have to be as fast as needed to play in the range of time fixed in the environment.
Credits
We would like to thank Arthur Juliani for all his work and medium articles. Tambet Matiisen for his nice implementation of Gym-Minecraft.
References
- Human-level control through deep reinforcement learning
- Deep Recurrent Q-Learning for Partially Observable MDPs - Matthew Hausknecht and Peter Stone
- Deep Reinforcement Learning with Double Q-learning - Hado van Hasselt and Arthur Guez and David Silver
- Teacher-Student Curriculum Learning - Tambet Matiisen and Avital Oliver and Taco Cohen and John Schulman
- Deep Learning for Video Game Playing - Niels Justesen and Philip Bontrager and Julian Togelius and Sebastian Risi