
Bioinformaticians and data scientists, rely on computational frameworks (e.g. snakemake, nextflow, CWL, WDL) to process, analyze and integrate data of various types. Such frameworks allow scientists to combine software and custom tools of different origin in a unified way, which lets them reproduce the results of others, or reuse the same pipeline on different datasets. One of the fundamental issues is that the majority of the users execute multiple pipelines at the same time, or execute a multistep pipeline for a big number of datasets, or both, making it hard to track the execution of the individual steps or monitor which of the processed datasets are complete. panoptes is a tool that monitors the execution of such workflows.
panoptes is a service that can be used by:
- Data scientists, bioinformaticians, etc. that want to have a general overview of the progress of their pipelines and the status of their jobs
- Administrations that want to monitor their servers
- Web developers that want to integrate the service in bigger web applications
Note: panoptes is in early development stage and the first proof of concept server will support only workflows written in snakemake.
Installation
Requirements:
- Python>=3.6
- virtualenv
- sqlite3
Local
pypi
Create virtual environment
virtualenv -p `which python3` venvActivate virtual environment
source venv/bin/activateInstall via pypi
pip install panoptes-uiconda
Create conda environment
conda create --name panoptes -c conda-forge -c bioconda panoptes-uiActivate conda environment
conda activate panoptesSource code
Clone repo
git clone https://github.com/panoptes-organization/panoptes.gitEnter repo
cd panoptesCreate virtual environment
virtualenv -p `which python3` venvActivate virtual environment
source venv/bin/activateInstall all requirements
pip install .Run the server
By default, server should run on 127.0.0.1:5000, and generate the sqlite database .panoptes.db.
Using the development server
panoptesUsing a WSGI server
Install all necessary packages (see above), plus a WSGI server (e.g. gunicorn or waitress), and run the server:
gunicorn --access-logfile logs/access.log --error-logfile logs/error.log --timeout 120 --bind :5000 panoptes.app:appContainers
Docker
Requirements:
- docker
Pull image that is automatically built from bioconda. You can find the latest tag in the following url: https://quay.io/repository/biocontainers/panoptes-ui?tab=tags. For example:
docker pull quay.io/biocontainers/panoptes-ui:0.2.3--pyh7cba7a3_0Then run the container with:
docker run -p 5000:5000 -it "image id" panoptesNote: In this case the database is stored within the docker image, so every time you restart the server the database will be empty. You would need to mount the volumes to make the database persistent.
Docker compose
Requirements:
- docker
- docker-compose
Build
docker-compose buildRun
docker-compose up -dServer should run on: http://127.0.0.1:8000
Stop
docker-compose downSingularity
You can also deploy the server with singularity. To do so pull the image with singularity. For example:
singularity pull docker://quay.io/biocontainers/panoptes-ui:0.2.2--pyh7cba7a3_0And then we can start the server by running:
singularity exec panoptes-ui:0.2.2--pyh7cba7a3_0Run an example workflow
In order to run an example workflow please follow the instructions here
panoptes in action
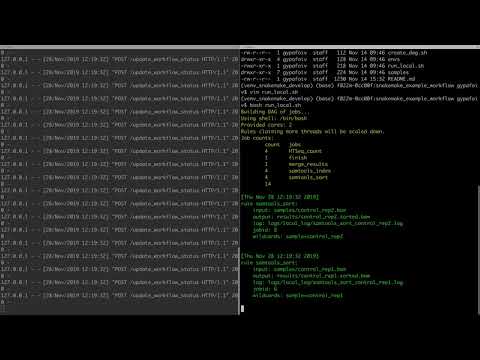
panoptes API
Panoptes provides the following API endpoints:
| Endpoint | Method | Description |
|---|---|---|
/api/service-info |
GET |
Server status |
/api/workflows |
GET |
Get all workflows |
/api/workflow/<workflow-id> |
GET |
Get workflow status |
/api/workflow/<workflow-id>/jobs |
GET |
Get all jobs of a workflow |
/api/workflow/<workflow-id>/job/<job-id> |
GET |
Get job status |
/api/workflow/<workflow-id> |
PUT |
Rename a workflow Expects a dictionary with new name (e.g. {'name': 'my new workflow name'}) |
/api/workflow/<workflow-id> |
DELETE |
Delete a workflow |
/api/workflows/all |
DELETE |
Clean up database |
To communicate with panoptes the following endpoints are used by snakemake:
| Endpoint | Method | Description |
|---|---|---|
/api/service-info |
GET |
Server status (same as above) |
/create_workflow |
GET |
Get a unique id/name str(uuid.uuid4()) for each workflow |
/update_workflow_status |
POST |
Panoptes receives a dictionary from snakemake that contains: - A log message dictionary - The current timestamp - The unique id/name of the workflow. (e.g. {'msg': repr(msg), 'timestamp': time.asctime(), 'id': id}) |
Contribute
Please see the Contributing instructions.
CI server
Changes in develop or master trigger a GitHub Actions build (and runs tests)
Contact
In case the issues section is not enough for you, you can also contact us via discord