 OpenScene: 3D Scene Understanding with Open Vocabularies
OpenScene: 3D Scene Understanding with Open Vocabularies
Songyou Peng
·
Kyle Genova
·
Chiyu "Max" Jiang
·
Andrea Tagliasacchi
Marc Pollefeys
·
Thomas Funkhouser
CVPR 2023
Paper | Video | Project Page
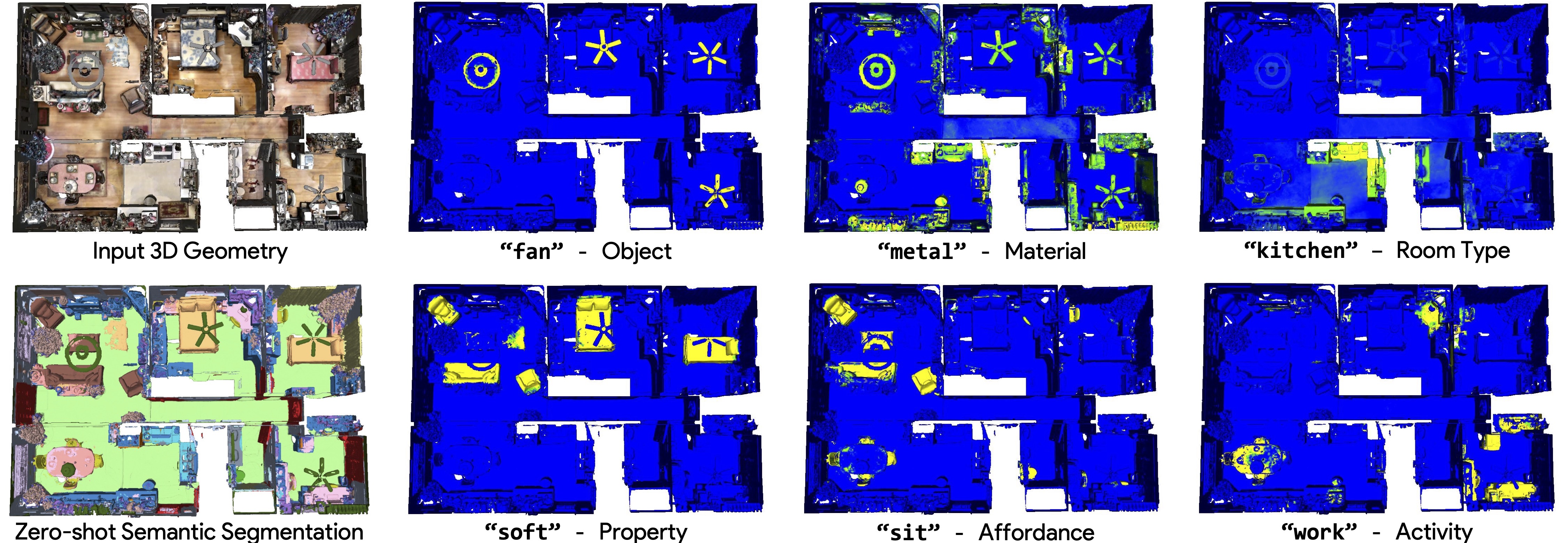
OpenScene is a zero-shot approach to perform a series of novel 3D scene understanding tasks using open-vocabulary queries.
Table of Contents
News :triangular_flag_on_post:
- [2023/10/27] Add the code for LSeg per-pixel feature extraction and multi-view fusion. Check this repo.
- [2023/03/31] Code is released.
Interactive Demo
No GPU is needed! Follow this instruction to set up and play with the real-time demo yourself.

Here we present a real-time, interactive, open-vocabulary scene understanding tool. A user can type in an arbitrary query phrase like snoopy (rare object), somewhere soft (property), made of metal (material), where can I cook? (activity), festive (abstract concept) etc, and the correponding regions are highlighted.
Installation
Follow the installation.md to install all required packages so you can do the evaluation & distillation afterwards.
Data Preparation
We provide the pre-processed 3D&2D data and multi-view fused features for the following datasets:
- ScanNet
- Matterport3D
- nuScenes
- Replica
Pre-processed 3D&2D Data
You can preprocess the dataset yourself, see the data pre-processing instruction.
Alternatively, we have provided the preprocessed datasets. One can download the pre-processed datasets by running the script below, and following the command line instruction to download the corresponding datasets:
bash scripts/download_dataset.shThe script will download and unpack data into the folder data/. One can also download the dataset somewhere else, but link to the corresponding folder with the symbolic link:
ln -s /PATH/TO/DOWNLOADED/FOLDER dataList of provided processed data (click to expand):
- ScanNet 3D (point clouds with GT semantic labels) - ScanNet 2D (RGB-D images with camera poses) - Matterport 3D (point clouds with GT semantic labels) - Matterport 2D (RGB-D images with camera poses) - nuScenes 3D (lidar point clouds with GT semantic labels) - nuScenes 2D (RGB images with camera poses) - Replica 3D (point clouds) - Replica 2D (RGB-D images) - Matterport 3D with top 40 NYU classes - Matterport 3D with top 80 NYU classes - Matterport 3D with top 160 NYU classesNote: 2D processed datasets (e.g. scannet_2d) are only needed if you want to do multi-view feature fusion on your own. If so, please follow the instruction for multi-view fusion.
Multi-view Fused Features
To evaluate our OpenScene model or distill a 3D model, one needs to have the multi-view fused image feature for each 3D point (see method in Sec. 3.1 in the paper).
You can run the following to directly download provided fused features:
bash scripts/download_fused_features.shList of provided fused features (click to expand):
- ScanNet - Multi-view fused OpenSeg features, train/val (234.8G) - ScanNet - Multi-view fused LSeg features, train/val (175.8G) - Matterport - Multi-view fused OpenSeg features, train/val (198.3G) - Matterport - Multi-view fused OpenSeg features, test set (66.7G) - Replica - Multi-view fused OpenSeg features (9.0G) - Matterport - Multi-view fused LSeg features (coming) - nuScenes - Multi-view fused OpenSeg features (coming) - nuScenes - Multi-view fused LSeg features (coming)Alternatively, you can also generate multi-view features yourself following the instruction.
Run
When you have installed the environment and obtained the processed 3D data and multi-view fused features, you are ready to run our OpenScene disilled/ensemble model for 3D semantic segmentation, or distill your own model from scratch.
Evaluation for 3D Semantic Segmentation with a Pre-defined Labelsets

Here you can evaluate OpenScene features on different dataset (ScanNet/Matterport3D/nuScenes/Replica) that have pre-defined labelsets. We already include the following labelsets in label_constants.py:
- ScanNet 20 classes (
wall,door,chair, ...) - Matterport3D 21 classes (ScanNet 20 classes +
floor) - Matterport top 40, 80, 160 NYU classes (more rare object classes)
- nuScenes 16 classes (
road,bicycle,sidewalk, ...)
The general command to run evaluation:
sh run/eval.sh EXP_DIR CONFIG.yaml feature_typewhere you specify your experiment directory EXP_DIR, and replace CONFIG.yaml with the correct config file under config/. feature_type corresponds to per-point OpenScene features:
fusion: The 2D multi-view fused featuresdistill: features from 3D distilled modelensemble: Our 2D-3D ensemble features
To evaluate with distill and ensemble, the easiest way is to use a pre-trained 3D distilled model. You can do this by using one of the config files with postfix _pretrained.
For example, to evaluate the semantic segmentation on Replica, you can simply run:
# 2D-3D ensemble
sh run/eval.sh out/replica_openseg config/replica/ours_openseg_pretrained.yaml ensemble
# Run 3D distilled model
sh run/eval.sh out/replica_openseg config/replica/ours_openseg_pretrained.yaml distill
# Evaluate with 2D fused features
sh run/eval.sh out/replica_openseg config/replica/ours_openseg_pretrained.yaml fusionThe script will automatically download the pretrained 3D model and run the evaluation for Matterport 21 classes.
You can find all outputs in the out/replica_openseg.
For evaluation options, see under TEST inside config/replica/ours_openseg_pretrained.yaml. Below are important evaluation options that you might want to modify:
labelset(default: None,scannet|matterport|matterport40|matterport80|matterport160): Evaluate on a specific pre-defined labelset in label_constants.py. If not specified, same as your 3D point cloud folder nameeval_iou(default: True): whether evaluating the mIoU. Set toFalseif there is no GT labelssave_feature_as_numpy(default: False): save the per-point features as.npyprompt_eng(default: True): input class name X -> "a X in a scene"vis_gt(default: True): visualize point clouds with GT semantic labelsvis_pred(default: True): visualize point clouds with our predicted semantic labelsvis_input(default: True): visualize input point clouds
If you want to use a 3D model distilled from scratch, specify the model_path to the correponding checkpoints EXP/model/model_best.pth.tar.
Distillation
Finally, if you want to distill a new 3D model from scratch, run:
-
Start distilling:
sh run/distill.sh EXP_NAME CONFIG.yaml -
Resume:
sh run/resume_distill.sh EXP_NAME CONFIG.yaml
For available distillation options, please take a look at DISTILL inside config/matterport/ours_openseg.yaml
Using Your Own Datasets
- Follow the data preprocessing instruction, modify codes accordingly to obtain the processed 2D&3D data
- Follow the feature fusion instruction, modify codes to obtain multi-view fused features.
- You can distill a model on your own, or take our provided 3D distilled model weights (e.g. our 3D model for ScanNet or Matterport3D), and modify the
model_pathaccordingly. - If you want to evaluate on a specific labelset, change the
labelsetin config.
Applications
Besides the zero-shot 3D semantic segmentation, we can perform also the following tasks:
- Open-vocabulary 3D scene understanding and exploration: query a 3D scene to understand properties that extend beyond fixed category labels, e.g. materials, activity, affordances, room type, abstract concepts...
- Rare object search: query a 3D scene database to find rare examples based on their names
- Image-based 3D object detection: query a 3D scene database to retrieve examples based on similarities to a given input image
Acknowledgement
We sincerely thank Golnaz Ghiasi for providing guidance on using OpenSeg model. Our appreciation extends to Huizhong Chen, Yin Cui, Tom Duerig, Dan Gnanapragasam, Xiuye Gu, Leonidas Guibas, Nilesh Kulkarni, Abhijit Kundu, Hao-Ning Wu, Louis Yang, Guandao Yang, Xiaoshuai Zhang, Howard Zhou, and Zihan Zhu for helpful discussion. We are also grateful to Charles R. Qi and Paul-Edouard Sarlin for their proofreading.
We build some parts of our code on top of the BPNet repository.
TODO
- [ ] Support demo for arbitrary scenes
- [ ] Support in-webiste demo
- [x] Support multi-view feature fusion with LSeg
- [x] Add missing multi-view fusion LSeg feature for Matterport & nuScenes
- [x] Add missing multi-view fusion OpenSeg feature for nuScenes
- [x] Multi-view feature fusion code for nuScenes
- [ ] Support the latest PyTorch version
We are very much welcome all kinds of contributions to the project.
Citation
If you find our code or paper useful, please cite
@inproceedings{Peng2023OpenScene,
title = {OpenScene: 3D Scene Understanding with Open Vocabularies},
author = {Peng, Songyou and Genova, Kyle and Jiang, Chiyu "Max" and Tagliasacchi, Andrea and Pollefeys, Marc and Funkhouser, Thomas},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}