![]()
![]()
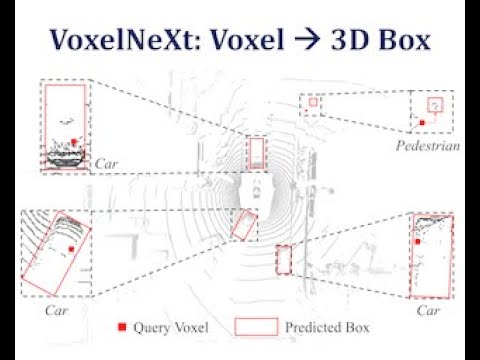
VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking (CVPR 2023)
This is the official implementation of VoxelNeXt (CVPR 2023). VoxelNeXt is a clean, simple, and fully-sparse 3D object detector. The core idea is to predict objects directly upon sparse voxel features. No sparse-to-dense conversion, anchors, or center proxies are needed anymore. For more details, please refer to:
VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking [Paper]
Yukang Chen, Jianhui Liu, Xiangyu Zhang, Xiaojuan Qi, Jiaya Jia

News
- [2023-04-23] We update the Argoverse2 dataset code. For Argoverse2, document and the pre-train weight are updated.
- [2023-04-19] We merged VoxelNeXt into Grounded-Segment-Anything.
- [2023-04-16] We released an example config file to train VoxelNeXt on KITTI.
- [2023-04-14] We combine VoxelNeXt and Segment Anything in 3D-Box-Segment-Anything. It extends Segment Anything to 3D perception and enables promptable 3D object detection.
- [2023-04-03] VoxelNeXt is merged into the official OpenPCDet codebase.
- [2023-01-28] VoxelNeXt achieved the SOTA performance on the Argoverse2 3D object detection.
- [2022-11-11] VoxelNeXt achieved 1st on the nuScenes LiDAR tracking leaderboard.
Experimental results
| nuScenes Detection | Set | mAP | NDS | Download |
|---|---|---|---|---|
| VoxelNeXt | val | 60.5 | 66.6 | Pre-trained |
| VoxelNeXt | test | 64.5 | 70.0 | Submission |
| +double-flip | test | 66.2 | 71.4 | Submission |
| nuScenes Tracking | Set | AMOTA | AMOTP | Download |
|---|---|---|---|---|
| VoxelNeXt | val | 70.2 | 64.0 | Results |
| VoxelNeXt | test | 69.5 | 56.8 | Submission |
| +double-flip | test | 71.0 | 51.1 | Submission |
| Argoverse2 | mAP | Download |
|---|---|---|
| VoxelNeXt | 30.5 | Pre-trained |
| Waymo | Vec_L1 | Vec_L2 | Ped_L1 | Ped_L2 | Cyc_L1 | Cyc_L2 |
|---|---|---|---|---|---|---|
| VoxelNeXt-2D | 77.94/77.47 | 69.68/69.25 | 80.24/73.47 | 72.23/65.88 | 73.33/72.20 | 70.66/69.56 |
| VoxelNeXt-K3 | 78.16/77.70 | 69.86/69.42 | 81.47/76.30 | 73.48/68.63 | 76.06/74.90 | 73.29/72.18 |
- We cannot release the pre-trained models of VoxelNeXt on Waymo dataset due to the license of WOD.
- For Waymo dataset, VoxelNeXt-K3 is an enhanced version of VoxelNeXt with larger model size.
- During inference, VoxelNeXt can work either with sparse-max-pooling or NMS post-processing. Please install our implemented spconv-plus, if you want to use the sparse-max-pooling inference. Otherwise, please use NMS post-processing by default.

Getting Started
Installation
a. Clone this repository
https://github.com/dvlab-research/VoxelNeXt && cd VoxelNeXtb. Install the environment
Following the install documents for OpenPCDet.
c. Prepare the datasets.
For nuScenes, Waymo, and Argoverse2 datasets, please follow the document in OpenPCDet.
Evaluation
We provide the trained weight file so you can just run with that. You can also use the model you trained.
cd tools
bash scripts/dist_test.sh NUM_GPUS --cfg_file PATH_TO_CONFIG_FILE --ckpt PATH_TO_MODEL
#For example,
bash scripts/dist_test.sh 8 --cfg_file PATH_TO_CONFIG_FILE --ckpt PATH_TO_MODELTraining
bash scripts/dist_train.sh NUM_GPUS --cfg_file PATH_TO_CONFIG_FILE
#For example,
bash scripts/dist_train.sh 8 --cfg_file PATH_TO_CONFIG_FILECitation
If you find this project useful in your research, please consider citing:
@inproceedings{chen2023voxenext,
title={VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking},
author={Yukang Chen and Jianhui Liu and Xiangyu Zhang and Xiaojuan Qi and Jiaya Jia},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
An introduction video on YouTube can be found here.
Acknowledgement
- This work is built upon the OpenPCDet and spconv.
- This work is motivated by FSD. And we follow FSD for the Argoverse2 data processing.
Our Works in LiDAR-based Autonumous Driving
- VoxelNeXt (CVPR 2023) [Paper] [Code] Fully Sparse VoxelNet for 3D Object Detection and Tracking.
- Focal Sparse Conv (CVPR 2022 Oral) [Paper] [Code] Dynamic sparse convolution for high performance.
- Spatial Pruned Conv (NeurIPS 2022) [Paper] [Code] 50% FLOPs saving for efficient 3D object detection.
- LargeKernel3D (CVPR 2023) [Paper] [Code] Large-kernel 3D sparse CNN backbone.
- SphereFormer (CVPR 2023) [Paper] [Code] Spherical window 3D transformer backbone.
- spconv-plus A library where we combine our works into spconv.
- SparseTransformer A library that includes high-efficiency transformer implementations for sparse point cloud or voxel data.
License
This project is released under the Apache 2.0 license.